Entity DSL
Contents
Purpose
The Entity DSL facilitates the handling of persistence entities. Defining entities using the Entity DSL efficiently creates a clean entity model that contains all relevant semantic elements of the model text file. This semantic model is used to automatically transform the semantic information into proper Java code with the respective annotations for a persistence provider. Additionally, if the entity model is located within a project with OSBP nature, "Auto-DTOs" and services are generated as well. In this case, attributes that are added to entities will automatically be transferred to the "Auto-DTOs".
Overview
The main semantic elements of the Compex Entity DSL are the following:
- "Package" - the root element that contains all the other elements. A model can contain multiple packages.
- "Import" declarations - used to import external models or even Java classes.
- "Datatype" declarations - a way to define datatypes that can be used in entities and beans.
- "Entity" - the abstraction of a business model entity. It contains further elements such as properties and references.
- "Bean" - does not compile to a JPA Entity but to a Java Bean (POJO with getter and setter and PropertyChange-Support). Beans may be used as temporary containers in entity operations or can be embedded into JPA Entities.
- "Enum" - the abstraction for Java enums.
- "Property" - a reference to an embedded Bean, an Enum, a Java class or a simple datatype (as defined in the datatype declaration). Offers multiplicity.
- "Reference" - a reference to another Entity (or to another Bean in the case of a Bean). Offers multiplicity.
- "Operations" - similar to Java methods. The Xbase expression language can be used to write high-level code.
- "Annotations" can be placed on Entity, Property and Reference.
- "Comments" can be added to all elements.
Entity model files
Entity models are described in .entitymodel files. These files describe the entity model and are the basis for the code generation. Entity models may be split over several .entitymodel files containing packages in the same namespace. An .entitymodel file may contain several packages with entities. However, from a performance point of view, a complex entity model may work better with more and smaller .entitymodel files than the same model crammed into a few large files (or even a single file).
package
Entity model files must start with a package declaration. Packages are the root element of the Entity DSL grammar. Everything is contained in a package: Imports, Entities, Beans and Enums have to be defined inside the Package definition. One document can contain multiple packages with unique names. The elements a package can contain are Entities, Beans and Enums. Additionally, a package allows Import statements and the declaration of datatypes.
package name {
import importStatement;
datatype datatypeDefinition;
entities/beans/enums
}

Marking a DTO as abstract (before the dto keyword) generates an abstract Java class for it.
The following modifiers may be placed after the dto keyword and the DTO name:
import
The Entity DSL allows the referencing of entities defined in different packages, even in different .entitymodel files. The import statement is a way to make these elements available in the current namespace without having to address them by their fully qualified name.
Import statements allow the use of the '*' wildcard.
import importStatement;

datatype
The Entity DSL allows the definition of datatypes. These are translated by the inferrer into their standard Java representation. The behavior of the generator can be controlled by the datatype definitions. Datatypes defined in an .entitymodel file are local to that file. In order to define datatypes in one place and have them available in multiple .entitymodel files, the datatypes may be defined in a ".datatypes" file containing only datatype definitions inside a package statement. There are three types of datatype definitions:
- jvmTypes: Datatype definitons that map types to jvmTypes take the basic syntax of
datatype <name> jvmType <type> as primitive;.Specifying datatypes in this manner uses an appropriate wrapper class in the generated Java code; adding the keywordsas primitiveenforces the use of primitive datatypes where applicable:
datatype foo jvmType Integer;compiles to anIntegerwhereasdatatype foo jvmType Integer as primitive;results inint. Figure 3: The defined datatype is translated to a wrapper class.
Figure 3: The defined datatype is translated to a wrapper class.
 Figure 4: By adding the
Figure 4: By adding theas primitivekeywords, the datatype is translated to a primitive datatype.


- dateTypes: The datatypes for handling temporal information can be defined by the following statement:
datatype <name> datetype date—time—timestamp;Datatypes that have been defined in this manner can be used as property variables in entities and beans.
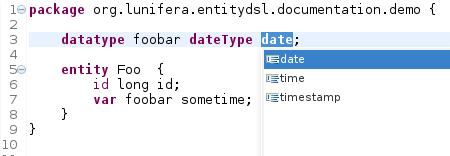 Figure 5: Defining datatypes for handling temporal information. Content assist is available.
Figure 5: Defining datatypes for handling temporal information. Content assist is available.

- blobs: Binary blobs can be handled by defining a datatype with the
as blobkeywords. The Java implementation of such a blob is a byte array. Appropriate persistence annotations are automatically added.
datatype <name> as blob; Figure 6: Including binary blobs by using a datatype with the
Figure 6: Including binary blobs by using a datatype with theas blobkeywords.

After import statements and datatype definitions, the content of the .entitymodel file is made up of entity, bean and enum definitions.
Entities
Entities are the most complex elements in the Entity DSL. An entity is an abstraction above a business object. Entities are defined by their name, properties, references and operations. Generally, an entity is an object which can keep the state of variables and references as well as be persisted. For each entity that is defined in a package, a Java class and the corresponding persistence structure is automatically generated. Inside a project with Compex nature, "Auto-DTOs" and services are created as well.
Entities may extend other entities. In this case, they are derived from their parent entity. That means that the properties and references of the parent entity are inherited.
Syntax:
[modifiers] entity <name> extends <parentEntity> {
[entityProperties]
}

import keyword and its fully qualified name
Entities may be defined with certain modifiers that change the generated Java Code. The following modifiers are supported:
abstract
abstractmarks the entity as "abstract". This generates an abstract Java class. Figure 8: The
Figure 8: Theabstractkeyword causes the translation into an abstract Java class

historized
historizedmarks the entity as "historized". Historized entities can have several entries in a database, but only one of them may be marked as current.The
historizedkeyword adds an object ID, a version field and a flag for the current version to the entity.
 Figure 9: The
Figure 9: Thehistorizedmodifier triggers the creation of an object ID, an object version and a flag for marking the current version.

cacheable
cacheablemarks the entity as "cacheable". The appropriate annotation for the persistence provider is added to the generated Java code. Figure 10: Declaring an entity to be
Figure 10: Declaring an entity to becacheableadds the@Cacheableannotation

timedependent
timedependentmarks the entity as "time-dependent". An object may have several entries in the database. Which entry is valid will be determined by valid from and valid until fields that are added to the entity. An object ID is created in order to tie the entries together. Thetimedependentkeyword recognizes the modifiers(DATE)and(TIMESTAMP). Default istimedependent(DATE).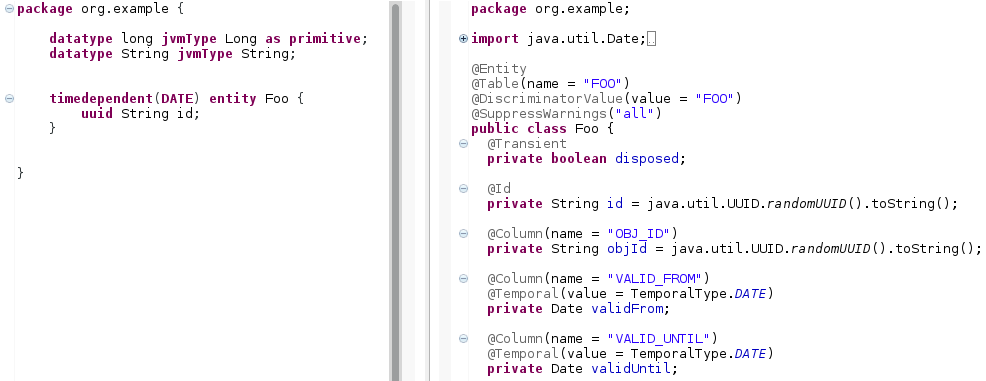 Figure 11: The
Figure 11: Thetimedependentkeyword causes an object ID, a validFrom and a validUntil field to be created in order to support multiple database entries for an object.

mapped superclass
mapped superclassmarks a class that provides persistent entity state and mapping information for its subclasses, but which is not an entity itself.Typically, the purpose of a mapped superclass is to define state and mapping information that is common to multiple entities. All the mappings from the mapped superclass are inherited by its subclasses, as if they had been defined there directly.
 Figure 12: The
Figure 12: Themapped superclasskeyword sets the appropriate annotation which causes the persistence provider to move the mappings to the derived subclasses.

extends
The modifier
extendsmay be placed after the entity keyword and the entity name, asentity foo extends bar {, wherebarhas already been defined as an entity.
extendsmarks an entity that is derived from another entity. That means that the properties and references of the parent entity are inherited.
Entity Persistence Settings
Apart from the mapped superclass modifier that moves all property columns to the tables belonging to derived classes, the following settings for table inheritance can be specified within an entity definition:
- inheritance per class
- inheritance per subclass
The structure of the database created from an entity model can be controlled by the following settings:
- schemaName
- tableName
- discriminatorColumn
- discriminatorType
- discriminatorValue
inheritance per class
inheritance per class{}causes a table to be created for each class; subclasses share this table using a discriminator value. This statement has to be followed by braces, inside of which further details can be specified. Figure 13: A single table for entity Base is created; the generated Java code for the “Derived” class shows that the “Derived” entity is added to this table by using a discriminator.
Figure 13: A single table for entity Base is created; the generated Java code for the “Derived” class shows that the “Derived” entity is added to this table by using a discriminator.

inheritance per subclass
inheritance per subclass{}causes a table to be created for each subclass. This statement has to be followed by braces, inside of which further details can be specified. This is the default behaviour if no inheritance strategy is specified. Figure 14: An
Figure 14: An@Tableannotation is added to the generated Java code, so that the "Derived" entity is mapped to a table of its own.

schemaName
schemaNameallows the specification of a name for the database schema to be used. This setting is translated to the appropriate JPA annotation@Table(schema = <xyz>). The schema name given is converted to snake case using capitals.
tableName
tableNameallows the specification of a name for the table (within the database schema) to which the entity is mapped. This setting is translated to the appropriate JPA annotation@Table(name = <xyz>).The table name specified is converted to snake case using capitals. The default value is the name of the entity.
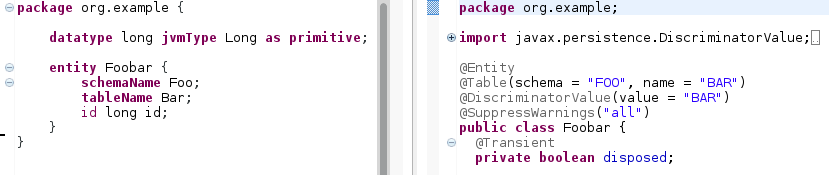 Figure 15: Specifying the
Figure 15: Specifying theschemaNameandtableNamesettings in an entity determines the name of the database schema and tables used for persistence.

discriminatorColumn
discriminatorColumnoptionally allows the specification of a name for the discriminator column in the case ofinheritance per class. It appears within the braces after the inheritance-strategy statement and must be followed by a semicolon. It defaults toDISC.
discriminatorType
discriminatorTypeoptionally allows the definition of the datatype of the discriminator within the single table. It can be set toCHAR,INT,STRINGorINHERIT. It appears within the braces after theinheritancestatement and must be followed by a semicolon. It defaults toSTRING;.
discriminatorValue
discriminatorValueallows a custom value to be used for the discriminator within the single table. It appears within the braces after theinheritancestatement and must be followed by a semicolon. It defaults to the entity name converted to snake case.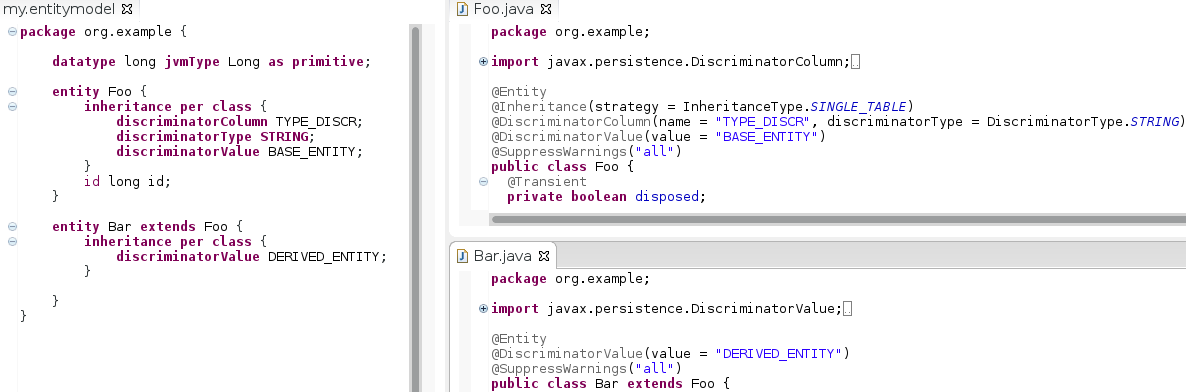 Figure 16: The
Figure 16: Theinheritancestatement allows the optional specification of discriminator column, type and value to be used in the case of a single table.

Beans
Beans are objects that are embedded in other entities, inheriting their persistence and lifecycle. Similar to entities, beans are characterised by their name, their properties and their references. For each bean that is defined in a package, a Java class is automatically generated.
Beans can be embedded into entities by defining them as properties of the respective entity. The appropriate annotations (@Embeddable, @Embedded, @AttributeOverrides etc.) are added in order to have beans persisted with their parent entities.

Enums
Enums are an abstraction of the Java enum. They compile to enum classes and can be used as properties in entities and beans.

enums allows using them as variables in entities and beans.Properties
Properties of entities and beans are references to datatypes or enums. They can be regarded as variables and are defined by a keyword followed by a datatype (Java type or datatype defined in the datatype section) and a name. By defining a bean as a property of an entity, it is embedded in it.
Properties can be determined with the following keywords:
var
The basic property
vardefines a variable that is persisted in a table column. A property must have a type and a name.Multiplicity of properties can be controlled by the following (optional) settings:
[1]defines a non-nullable property.[0..1]defines a nullable property (this is the default behavior).[1..*]defines a list of properties that must not be empty.[0..*]or simply[*]defines a list of properties that may be empty.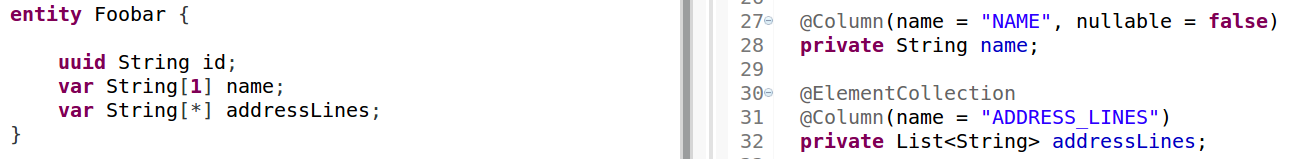 Figure 19: Variables can be defined using the
Figure 19: Variables can be defined using thevarkeyword.The appropriate persistence settings are generated automatically. If a multiplicity is specified, the appropriate annotations (and, if necessary, a list rather than a single variable) are generated.

derived
deriveddefines a property that is derived from other properties. The derived property must be have a type, a name and the calculation logic that derives it from the other properties, written as an Xexpression in braces.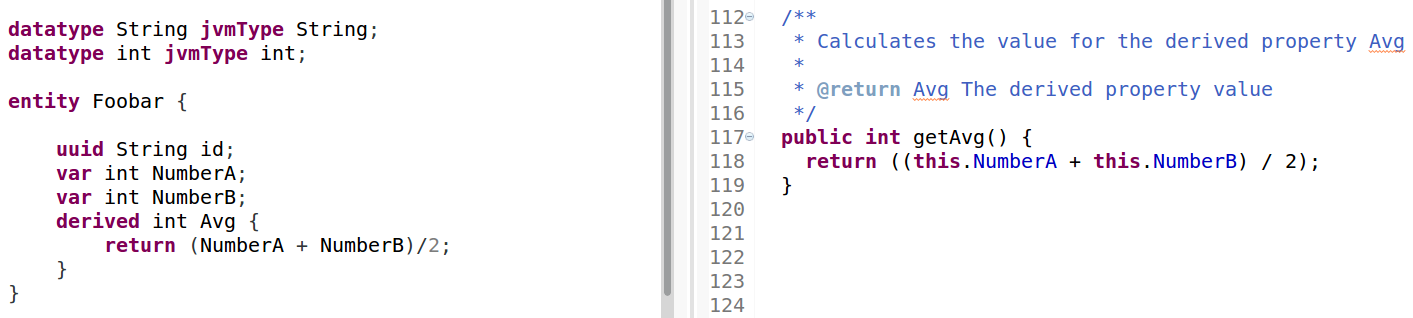 Figure 20: Properties may be derived from other properties using an Xexpression.
Figure 20: Properties may be derived from other properties using an Xexpression.The code is automatically translated to valid Java code.

dirty
dirtydefines a property used as a flag to track the "dirty" state of the buffered data when editing values, before the changes have been written back to the persistence entity. Only onedirtyflag is allowed per entity. The datatype has to be boolean. Figure 21: The
Figure 21: Thedirtyproperty is used to flag whether changes have been made to the bufered data, but not yet written back to the persistence entity.The boolean field for this property and the appropriate annotation are generated with the
dirtykeyword.

domainDescription
domainDescriptiondefines a property that is used as a domain description. The appropriate annotation is added to the property. A domain description must be of typeString. Domain descriptions may be derived from other properties. Figure 22: Domain description properties can be created with the
Figure 22: Domain description properties can be created with thedomainDescriptionkeyword.

domainKey
domainKeydefines a domain key. The appropriate annotation is added to the property. Primitive datatypes may be used as domain keys. Figure 23: A field containing a domain key is created with the
Figure 23: A field containing a domain key is created with thedomainKey keyword.

id
► -- deprecated -- deprecated -- deprecated -- deprecated -- deprecated -- deprecated -- deprecated -- deprecated --
id defines an ID property (used as a primary key by the JPA compiler). This keyword is deprecated - use uuid instead. If no
idis specified, a warning is given.Caution: ID autogeneration causes problems, since the value is not set before the entity is persisted, e.g., in the database. It is therefore advised to use the
uuidkeyword instead.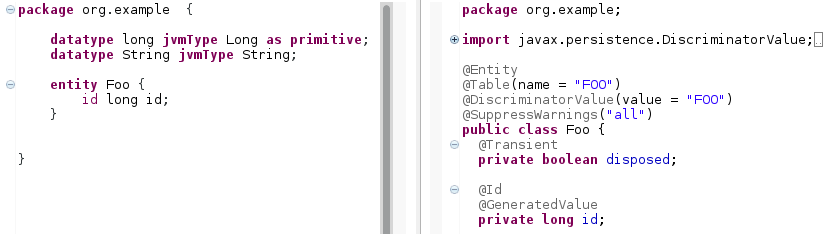 Figure 24: Entities are supposed to have an ID property that is used as a primary key to the underlying database.
Figure 24: Entities are supposed to have an ID property that is used as a primary key to the underlying database.Caution: The generated IDs are not necessarily unique if the deprecated
idkeyword is used!

index
The
indexkeyword causes an index for the table to be generated. Indexes may be based on one or more properties (primitive only) and references (one-to-one only) of the entity. An index must be given a name and, in braces, a list of the fields it is based upon. If theindexkeyword is prefixed withunique, a unique index is created. Figure 25: Database table indexes that map entities are generated with the
Figure 25: Database table indexes that map entities are generated with theindexkeyword.The
@Tableannotation is supplemented with the index definition.

properties
Features (properties and references) of entities and beans can optionally be given additional information in the form of key-value pairs. This information can then be retrieved from the semantic model. The key-value pairs are defined in parentheses after the properties keyword following the feature name. Multiple pairs can be defined (comma-separated).
 Figure 26: Additional information about features can be defined by key-value pairs. This information is then stored in the semantic model and is retrievable.
Figure 26: Additional information about features can be defined by key-value pairs. This information is then stored in the semantic model and is retrievable.

uuid
uuidallows the use of Universally Unique IDs as primary keys. A new UUID value is generated for each object as soon as that object has been created, independently of database operations. This circumvents the problems with theidkeyword. UUIDs have to be of typeString.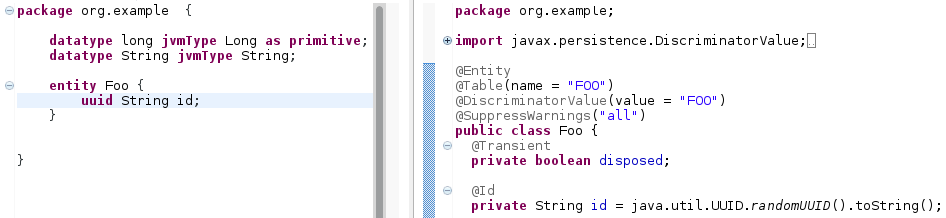 Figure 27: By using the
Figure 27: By using theuuidkeyword, entities are created with a reliably unique identifier.

version
versiondefines a version-property (used by the JPA-Compiler).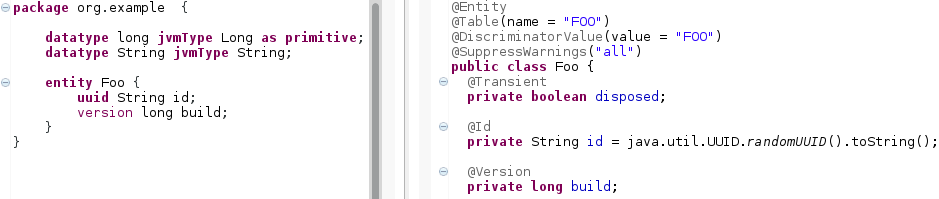 Figure 28: A
Figure 28: Aversionproperty can be added to entities and beans.

transient
transientmarks the property as transient. Instead of a@Column, a@Transientannotation is generated, so that the property is not persisted in the database.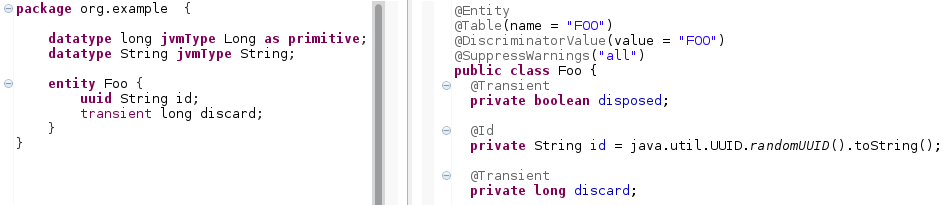 Figure 29: The
Figure 29: Thetransientkeyword enables the exclusion of properties from persistence.

References
The Entity DSL tracks relationships between entities by using the concept of "references". References can exist between objects of the same nature (entities to entities, beans to beans). Where appropriate, back references ("opposite") are added.
References are defined by the ref keyword, a target, an optional type and a name. The exact type of the reference can be specified with the following modifiers:
Multiplicity and nullability
The Entity DSL supports the specification of multiplicities in square brackets appended to the type:
[1]defines a non-nullable, one-to-one relationship.[0..1]defines a nullable, one-to-one relationship (this is the default behavior).[1..*]defines a non-nullable, one-to-many relationship. Anoppositereference is needed.[0..*]or simply[*]defines a nullable, one-to-many relationship. Anoppositereference is needed.
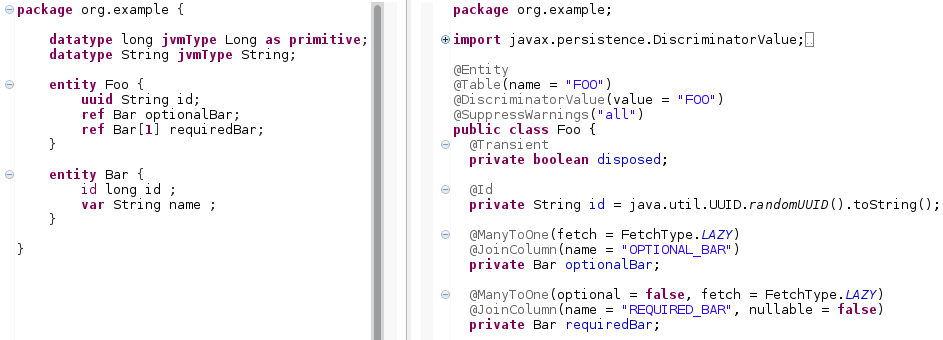 Figure 30: Adding multiplicity "[1]" causes the annotations for non-nullable database entries to be set.
Figure 30: Adding multiplicity "[1]" causes the annotations for non-nullable database entries to be set.

opposite reference
Lifecycle references need the specification of an opposite reference. This can be done with the
oppositekeyword.Using the
oppositereference, it is possible to navigate back to the original object after following the reference.
cascade
The
cascadespecifier controls the behavior of the database on delete operations. If an object with acascadereference to other objects is deleted, those other objects will be removed as well.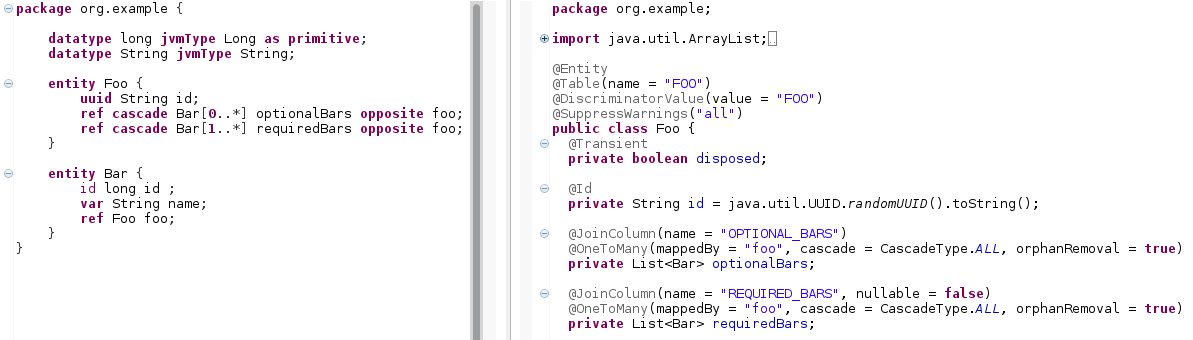 Figure 31: By using the
Figure 31: By using thecascadeandoppositekeywords, bidirectional associations can be achieved.

Operations
Operations are other important features. They are based on Xbase and offer a huge set of semantic features, extending the featureset of Java. Xbase additionally offers features such as closures.
Operations can be declared by the def keyword followed by braces containing the inline operation.

def keyword allows the inlining of custom methods in the Entity DSL code.These methods are translated into the appropriate Java methods along with the automatically generated getter and setter methods.
Operations can be combined with the Annotations @PrePersist,@PreUpdate, etc. They will be executed when the entity is persisted, updated, etc. More details can be found here
It is possible to use the same annotation multiple times, they will be executed one after the ofter. The @PostPersist and @PostUpdate operations will be executed in an asynchronos way to unblock the userinterface. This may lead to a delay in execution, if there are many requests at a time.
Annotations
Annotations can be added to all elements except import declarations. Specifying annotations in the Entity DSL works in a straightforward manner; content assist is available. The added annotations are taken over into the generated Java code.

These methods are translated into the appropriate Java methods along with the automatically generated getter and setter methods.
Comments
Comments can be added anywhere in an .entitymodel text file and are copied over into the generated Java code. Comments are enclosed in /* ... */.

Comments before the package keyword are copied over to all generated Java classes – this is the place for copyright notices.

Reserved Keywords
The keywords of the Entity DSL are syntactic features and can therefore not be used as semantic identifiers.
In order to circumvent this, it is possible to escape them with the ^ character. During the generation of the Java code, this escape character is removed.

uuid is generated that cannot be specified in the entity model file.
Please note that you are not allowed to use identifiers corresponding to reserved keywords of the supported databases you can find here below:
[https://dev.mysql.com/doc/refman/8.0/en/keywords.html MySQL]
[https://www.postgresql.org/docs/8.2/sql-keywords-appendix.html PostgreSQL]
Copyright Notice
All rights are reserved by Compex Systemhaus GmbH. In particular, duplications, translations, microfilming, saving and processing in electronic systems are protected by copyright. Use of this manual is only authorized with the permission of Compex Systemhaus GmbH. Infringements of the law shall be punished in accordance with civil and penal laws. We have taken utmost care in putting together texts and images. Nevertheless, the possibility of errors cannot be completely ruled out. The Figures and information in this manual are only given as approximations unless expressly indicated as binding. Amendments to the manual due to amendments to the standard software remain reserved. Please note that the latest amendments to the manual can be accessed through our helpdesk at any time. The contractually agreed regulations of the licensing and maintenance of the standard software shall apply with regard to liability for any errors in the documentation. Guarantees, particularly guarantees of quality or durability can only be assumed for the manual insofar as its quality or durability are expressly stipulated as guaranteed. If you would like to make a suggestion, the Compex Team would be very pleased to hear from you.
(c) 2016-2026 Compex Systemhaus GmbH