Difference between revisions of "OS.bee Documentation for Designer"
(→Surrogate or natural keys in entity models?) |
(→Surrogate or natural keys in entity models?) |
||
| Line 1,508: | Line 1,508: | ||
I found this excellent article that explains in detail the pros and cons: | I found this excellent article that explains in detail the pros and cons: | ||
| − | [https://www.zdnet.de/41553179/surrogat-oder-natuerlicher-schluessel-so-trifft-man-die-richtige-entscheidung/ Surrogate or natural key: How to make the right decision] | + | '''[https://www.zdnet.de/41553179/surrogat-oder-natuerlicher-schluessel-so-trifft-man-die-richtige-entscheidung/ Surrogate or natural key: How to make the right decision]''' |
| − | + | : The superiority of surrogate keys compared to natural keys is a much debated issue among database developers. ZDNet provides tips on when and why which type of key should be preferred. | |
| − | + | :: ''by Susan Harkins on May 19, 2011, 4:00 pm'' | |
According to relational database theory, a correctly normalized table must have a primary key. However, database developers are arguing over whether surrogate keys or natural keys are better. Data contains a natural key. A surrogate key is a meaningless value that is usually generated by the system. Some developers use both types of keys, depending on the application and data, while others strictly adhere to a key type. | According to relational database theory, a correctly normalized table must have a primary key. However, database developers are arguing over whether surrogate keys or natural keys are better. Data contains a natural key. A surrogate key is a meaningless value that is usually generated by the system. Some developers use both types of keys, depending on the application and data, while others strictly adhere to a key type. | ||
| Line 1,517: | Line 1,517: | ||
The following tips mostly prefer surrogate keys (as the author does), but there should be no stiffening on a key type. It is best to be practical, reasonable and realistic and to use the key that suits you best. However, every developer should keep in mind that he chooses to make a long-term choice, which affects others as well. | The following tips mostly prefer surrogate keys (as the author does), but there should be no stiffening on a key type. It is best to be practical, reasonable and realistic and to use the key that suits you best. However, every developer should keep in mind that he chooses to make a long-term choice, which affects others as well. | ||
# '''A primary key must be unique''' | # '''A primary key must be unique''' | ||
| − | # | + | #: A primary key uniquely identifies each entry in a table and links the entries to other data stored in other tables. A natural key may require multiple fields to create a unique identity for each entry. A surrogate key is already unique. |
# '''The primary key should be as compact as possible''' | # '''The primary key should be as compact as possible''' | ||
| − | # | + | #: In this case, compact means that not too many fields should be required to uniquely identify each entry. To obtain reliable data, multiple fields may be required. Developers who think natural keys are better often point out that using a primary key with multiple fields is no more difficult than working with a single-field primary key. In fact, it can be quite simple at times, but it can also make you desperate. |
| − | # | + | #: A primary key should be compact and contain as few fields as possible. A natural key may require many fields. A surrogate key requires only one field. |
# '''There can be natural keys with only one field''' | # '''There can be natural keys with only one field''' | ||
| − | # | + | #: Sometimes data has a primary key with only one field. Company codes, part numbers, seminar numbersand ISO standardized articles are examples of this. In these cases, adding a surrogate key may seem superfluous, but you should weigh your final decision carefully. Even if the data seems stable for the moment, appearances can be deceptive. Data and rules change (see point 4). |
# '''Primary key values should be stable''' | # '''Primary key values should be stable''' | ||
| − | # | + | #: A primary key must be stable. The value of a primary key should not be changed. Unfortunately, data is not stable. In addition, natural data is subject to business rules and other influences beyond the control of the developer. Developers know and accept that. |
| − | # | + | #: A surrogate key is a meaningless value without any relationship to the data, so there is no reason to ever change it. So when you're forced to change the value of a surrogate key, it means something has been wronged. |
# '''Know the value of the primary key to create the entry''' | # '''Know the value of the primary key to create the entry''' | ||
| − | # | + | #: The value of a primary key can never be zero. This means knowing the value of the primary key to create an entry. Should an entry be created before the value of the primary key is known? In theory, the answer to this is no. However, practice sometimes forces one to do so. |
| − | # | + | #: The system creates surrogate key values when a new entry is created so that the value of the primary key exists as soon as the entry exists. |
# '''No duplicate entries are allowed''' | # '''No duplicate entries are allowed''' | ||
| − | # | + | #: A normalized table can not contain duplicate entries. Although this is possible from a mechanical point of view, it contradicts relational theory. Also, a primary key can not contain duplicate values, with a unique index preventing duplicate values. These two rules complement each other and are often cited as arguments for natural keys. The proponents of natural keys point out that a surrogate key allows for duplicate entries. If you want to use a surrogate primary key, just apply an index to the corresponding fields and the problem is solved. |
# '''Users want to see the primary key''' | # '''Users want to see the primary key''' | ||
| − | # | + | #: There is a misunderstanding about the user's need to know the value of the primary key. There is no reason, theoretical or otherwise, for users to see the primary key value of an entry. In fact, users do not even need to know that such a value exists. It is active in the background and has no meaning to the user as he enters and updates this data, runs reports, and so on. There is no need to map the primary key value to the entry itself. Once you've got rid of the idea that users need the primary key value, you're more open to using a surrogate key. |
# '''Surrogate keys add an unnecessary field''' | # '''Surrogate keys add an unnecessary field''' | ||
| − | # | + | #: Using a surrogate key requires an extra field, which some consider a waste of space. Ultimately, everything needed to uniquely identify the entry and associate it with data in other tables already exists in the entry. So why add an extra column of data to accomplish what the data alone can do? |
| − | # | + | #: The cost of a self-generating value field is minimal and requires no maintenance. Taken alone, this is not a sufficient reason for recommending a natural key, but it is a good argument. |
# '''Do not systems make mistakes?''' | # '''Do not systems make mistakes?''' | ||
| − | # | + | #: Not everyone trusts system-generated values. Systems can make mistakes. This basically never happens, but it is theoretically possible. On the other hand, a system susceptible to this type of disturbance can also have problems of natural value. To be clear, the best way to protect a complete database, not just the primary key values, is to make regular backups of it. Natural data is also no more reliable than a system-generated value. |
# '''Some circumstances seem to require a natural key''' | # '''Some circumstances seem to require a natural key''' | ||
| − | # | + | #: The only reason a natural key might be required is for integrated system entries. In other words, sometimes applications that share similar tables create new entries independently. If you do not make any arrangements, the two databases will probably generate the same values. A natural key in this case would prevent any duplicate primary key values. |
| − | # | + | #: There are simple tricks to use a surrogate key here. Each system can be given a different starting value, but even that can cause problems. GUIDs work, but often affect performance. Another alternative would be a combined field from the system-generated field of the entry and a source code that is used only when connecting the databases. There are other possibilities, although a natural key seems to be the most reasonable option in this situation. |
After reading this article you probably wouldn't ask me again, would you? You would, I know it. | After reading this article you probably wouldn't ask me again, would you? You would, I know it. | ||
Revision as of 11:36, 2 August 2018
Contents
- 1 OS.bee Documentation for Designer
- 1.1 Get Started
- 1.2 Modeling
- 1.2.1 Display of article description
- 1.2.2 I18N.properties (Reorganization of obsoleted values)
- 1.2.3 Display values from ENUMS in Table
- 1.2.4 References to images
- 1.2.5 Perspective with master/slave relationship
- 1.2.6 Perspective use border to show boundary for each sash
- 1.2.7 Datainterchange Export (does not overwrite existing file)
- 1.2.8 Logged in user as part of the data-record
- 1.2.9 bpmn2 file reference in blip-DSL
- 1.2.10 How to add the missing icon images to a new created ENUM combo box
- 1.2.11 table DSL (as grid) create new data records
- 1.2.12 DSL entity (Multiplicity of properties)
- 1.2.13 UI-Design
- 1.2.14 DSL Dialog: Autosuggestion for DomainKey or DomainDescritpion
- 1.2.15 DSL Table
- 1.2.16 datamart DSL (condition filtered) table does not refresh
- 1.2.17 DSL authorization (CRUD)
- 1.2.18 DSL Menu(UserFilter/SuperUser)
- 1.2.19 Printer Selection (Default Printer)
- 1.2.20 DSL Entity Enum with own images
- 1.2.21 How to synchronize views
- 1.2.22 How to get new features from your toolbar
- 1.2.23 Add user information to your CRUD operations
- 1.2.24 Designing dialogs using multiple columns
- 1.2.25 Grouping attributes on dialogs
- 1.2.26 How units of measurements are handled
- 1.2.27 How sliders can improve the user experience with your dialogs
- 1.2.28 New ways to supply icons for enum literals
- 1.2.29 Validation
- 1.2.30 Extended Validation
- 1.2.31 Reset cached data
- 1.2.32 ReportDSL: How to get a checkbox for a Boolean attribute
- 1.2.33 How to collect business data and presenting meaningful statistics with OS.bee - INTRODUCTION
- 1.2.34 How to collect business data and presenting meaningful statistics with OS.bee – PART1
- 1.2.35 How to collect business data and presenting meaningful statistics with OS.bee – PART2
- 1.2.36 How to collect business data and presenting meaningful statistics with OS.bee – PART3
- 1.2.37 How to collect business data and presenting meaningful statistics with OS.bee – PART4
- 1.2.38 Surrogate or natural keys in entity models?
- 1.3 Core Dev
- 1.3.1 New event for statemachines
- 1.3.2 Duplicate translations
- 1.3.3 Edit WelcomeScreen
- 1.3.4 Search
- 1.3.5 DataInterchange is externally configurable by admins
- 1.3.6 Statemachine (FSM) handles external displays
- 1.3.7 Database Support
- 1.3.8 Combo box handles now more complex objects
- 1.3.9 Enriching csv files to highlight complex information
- 1.3.10 Max File Size BlobMapping
- 1.3.11 How to show JavaScript compile errors building the Widgetset
- 1.4 Apps
- 2 Copyright Notice
OS.bee Documentation for Designer
Here are frequently asked questions from designers which are not mentioned by other Documentation. In this Page, you could find the answer to your question.
Get Started
Pitfalls with new Eclipse installations
Be aware that when installing a new Eclipse environment to look at the preferences for DS Annotations and check the box "Generate descriptors from annotated sources" as OS.bee makes heavy use of automatically generated component descriptors in the OSGI-INF directory. It is unchecked by default for incomprehensible reasons.

Don't forget to set your target platform correctly as described in the installation guide.
Eclipse Installation / Installation SWF / New Project from GIT
Question:
Using Eclispe Neon, execution of Installation Software-Factory as described in the Installation notes, Connect to a GIT Archiv, After Building Workspace the application is not valid (see Screen-Shot) Try to clean the Project was not successful.

Answer:
The version of the installed Software Factory and the version needed for the project do not match.
Please install the appropriate Software Factory version.
cvs2app - question regarding ENUM types
Question:
cvs2app is mentioned in the documentation "App up in 5 minutes" and gives the possibility to create one app directly out of the csv file. One of the first steps is to create an entity, which is generated based on the information on the first line (which contains the column names). In consequence I have 2 questions regarding ENUMS:
- Is it possible to create an entity ENUM out the csv - FILE?
- Is it possible to use an existing ENUM entity during the creation of the app?
For example:
in the entity there is already a definition:
enum type_ps {
PROCESS_DESCRIPTION, ORGANISATIONAL
}
and the csvfile looks as follows:
ticket_type_number;ticket_type_description;ticket_type_ps_type
1;CRS handling;PROCESS_DESCRIPTION
2;Administrative;ORGANISATIONAL
3;Delivery package;ORGANISATIONAL
4;Software behaviour;PROCESS_DESCRIPTION
Answer:
Yes it is possible. When using the latest version (from feb 2018), it is possible to supply various meta-information to each column. One meta-info is the hint to the application builder that this column is meant to be a ENUM. By default it wouldn't be possible to guess that fact.
Launch Application from Eclipse (very slow)
Question:
When starting the Application from within the Eclipse it took very long time until the application is up. Are there some settings to be controlled?
Answer:
If you experience very slow performance with Eclipse itself as well as the application you launch from Eclipse it might be a good idea to check the virus scanner you have installed. Some virus scanners check all the files inside the Eclipse installation directory, the Eclipse workspace and the GIT repository which might lead to extreme slow performance. Ask your Administrator how to avoid this.
Structure of the documentation page
In the OS.bee Software Factory Documentation page, there are 3 Headlines used to structure the page:
- OS.bee DSL Documentation
- Other OS.bee-Specific Solutions
- OS.bee Third-Party Software Solutions
At the end of Chapter one there are some helpful hints to work with eclipse. To start with Eclipse and the SWF these hints could be very useful.
- One more hint: to Use STRG-Shift-O to organize the import inside the DSL.
Modeling
Display of article description
Question:
I would like to match the article number to the name of the article on a dialog box (field is not editable). The grammar of the dialogue gives me little meaningful ways to specify fields. The "autowire" and "view" probably do not help here - the manual does not help me any further.
One more example to make it clearer: A GTIN is scanned - the GTIN appears in the GTIN field and the article description in the Label field, the unit of measure in the Unit of measure field
Answer:
I assume you mean the descriptor of a relation of cardinality many to one in a combo box. For the time being the entries in the combo box are identical with the one which is selected and therefore do not show more information as in the list. If the domainKey or domainDescription keyword at the owner entity of the many to one relationship decorates a certain attribute, this one will be the displayed value in the relationship-combo. As the displayed value is not important for the linking or unlinking of a relationship, but its underlying related datatype, you can also use a synthetic attribute as domainKey attribute. You could create a new attribute in the owner entity combining number and name. In the authorization DSL you could declare it invisible. Let it automatically be combined with a def statement in entity model.
In autobinding, there is no solution for this right now. In the ui dsl you can add bindings as desired. A solution could be the following: we introduce a modifyer (metaflag) to mark an entity attribute which is unexpessive (such as GTIN or item number or sku) without additional information. If the autobinding mechanism detects such an attribute it automatically adds the domainKey and/or domainDescription to the right of the unexpressive attribute. If the marked attribute itself is either a domainKey or domainDescription the respective missing part is added.
Please try the following solution for the number + description problem: create on the one side of a many to one relationship a domainKey attribute where you combine 2 or more attributed virtually. E.g. you name the attribute "productSearch". Then you create a method with the "def" keyword with a preceding annotation "@PostLoad". The effect is that whenever you load the domainKey, the system will call the annotated method and assign whatever you put inside the method to this domainKey attribute. Remember that attributes marked as domainKey or domainDescription will be shown in combo boxes as descriptors for the respective underlying DTO. An entity definition like:
entity ProductClass {
persistenceUnit "businessdata"
uuid String ^id
domainKey String productSearch
var String productSubcategory
var String productCategory
@PostLoad def void fillProductSearch() {
productSearch = productCategory + " - " + productSubcategory
}
}
This will lead to combo box entries that are combined of category and subcategory.
I18N.properties (Reorganization of obsoleted values)
Question:
Each DSL has its own I18N.properties to translate the values. The property file includes values that are no longer used in the Modell-Description. (For example based on an addition correction of orthography)
The update of the properties seems to be one-way. Is there a function to reorganize the values (with the target to drop all obsoleted values)?
Answer:
No, there is no way to delete unused entries for security reasons. Translations to foreign languages are expensive. The modeler is responsible to delete obsoleted entries.
Display values from ENUMS in Table
Question:
We are using a perspective with the combination of table and dialog to maintain master data. The dialog contains combo-boxes to select values based on ENUMS. The selected value is displayed in the dialog, but is not displayed in the table. Is there a way to display the values of the selected ENUM in the table, with the objective to use the filter?
Answer:
This is not yet implemented but on schedule.
References to images
Question:
Using for example MENU.DSL Documentation:
package <package name>[{
expandedImage <expandedImage String>
Keyword expandedImage and collapsedImage is used to define the menu image when the menu expanded or collapsed. Where can we find the valid names of the Images to use in the String?
Answer:
The images can be selected by using hitting <CTRL>+<space> right behind the keyword. This will lead you to the image picker. Double-click on "Select icon...“ , then you can select the image from the image pool. The corresponding name will be added to the model. If you want to add own images to the pool follow How to add pictures.
Perspective with master/slave relationship
Question:
We created a perspective with a "master" table and 5 related "slave" tables. The target is to select one row in the master table and automatically filter the data rows in the slave tables related to the selected data. Where can we find information about the way to realize this goal?
Answer:
With "master" you probably mean an entity that has relative to the "slave" an one2many relationship. Views of their underlying tables will synchronize if they share a filter with the selection of another table. The filter must use the same entity as the entity of a table that selected a row. So every datamart of a "slave" must have a condition in a many2one join where the "one" side is the entity that should synchronize while selecting rows. In effect the selected row tries to change all filters to the same ID if the same entity is used. This applies to all open views in all open perspectives. In datamartDSL, using the keyword "filtered", the result in the application is a combo-box in the header of the table, which allows to select a value which is used as a filter of all tables of the perspective which have use the same condition; using the keyword “selected”, the result will be a list-box.


Perspective use border to show boundary for each sash
Question:
Is it possible to show border between each sash-container used in a perspective? From our point of view the arrangement is not pretty clear to the user. It could be helpful to get a clearer view to show (optional) real visible border between sash-container and even between parts. for example:
- green border between parts of a sash-container
- blue border between sash-container

Is this already possible?
Answer:
For the moment there are no plans to colorize borders by means of grammar keywords. It is possible by changing the CSS for the currently selected theme.
Datainterchange Export (does not overwrite existing file)
Question:
We defined an interchange for a specific entity. The created TriggerView is called in a perspective, which is called in the menu. We also used an adjusted dialog with a toolbar with the export command. When the defined target filesystem is empty, the export file was created. A second try to export the data does not create a new file. Is there something to consider to allow an "overwrite" of existing data?
Answer:
Datainterchange tries not to overwrite already exported files and appends a running number to the end of the filename. When it is not work, you have to debug. The Action-buttons of the created Trigger-View are accidently colored as disabled but they are not. This will be changed in the future.

If you think they are very pale (not easy to read). It is also possible to define the layout of the buttons.
Logged in user as part of the data-record
Question:
We want to create an entity, where the logged in user, who insert a record is referenced in each data-record that be created. Is there a way (function or something else) to handle this request?
Answer:
This request is already a ticket.
bpmn2 file reference in blip-DSL
Question:
There is no hint about where to save the *.bmpn2 files. So we created a subfolder in net.osbee.app.XXX.model.blip, which is named of “bpm”. Using the new subfolder we created a new jBPM Process Diagram. As the description during the creation we remove "defaultPackage." as Prefix for Process-ID: The model is simple (Start-Event / User-Task / End-Event) When we try to reference the bpm2 model inside the blip-dsl, the name could not be resolved. Is there something to take care about?

Answer:
You must right click the new folder “bpm” and when the mouse is over "Build Path", select "use as source folder". After this is done you should press STRG+SHIFT+O in the Blip DSL to "organize imports".
How to add the missing icon images to a new created ENUM combo box
Question:
Defining an ENUM at the entity DSL model instance, a corresponding combo box is created, but the corresponding icon image for each ENUM component is missing.
Answer:
For the solution have a look at How to add pictures. We would like to enforce the usage of icons in OS.bee. So if you use EnumComboBox without images, there will be a "missing icon" icon appears in the combo-box, it was introduced with intent to remind the designer that there is a missing icon. There is still a problem, in the case, for example there are 10 Enum values per Enum type and 10 Enum types are used in an entity, 100 image names must be generated and deposited. Even if all use the same picture. This takes a lot of effort and costs time - just writing the file names per picture. Some of the designer wants to use EnumComboBox without images. Although great user experience comes from great effort, for designers who want to hold on to the slipshod way we will introduce a setting in OS.bee preferences to avoid displaying icons at all when at least one of the entries of a combo box is missing. For a pretty user experience we must decide between text and icon per combo box.
table DSL (as grid) create new data records
Question:
Is it possible to create new data records while using a grid? Existing data records can be changed for defined attributes (editable prop) using a double-click on the data row What must be changed to allow the creation of data rows?

Answer:
This is not yet possible, but on schedule.
DSL entity (Multiplicity of properties)
Question:
We defined an entity for customer data, with the goal that some attributes must be entered during creation of new data-records. To use only the property seems not to be enough to prevent a data-record to be saved, without filling non-nullable attributes. What have to be done to reach the goal?
Code-example:
var int [1]customer_no
var String [1] customer_name
var boolean portalrequired
var String country
Snippet of documentation

Answer:
This is a very interesting question. So I will explain some important facts about binding and validation (formerly known as Plausi). As OS.bee implements the Model-View-Controller pattern, UI fields, business logic and data layer are strictly separated. The link between them is realized by a "bean binding" mechanism. This mechanism propagates changes between the MVC elements in every desired direction. There is a layer between this mechanism which is called bean validation. For every direction of binding a validation can be implemented to avoid or allow a certain change. Even conversions between values from model to presentation and vice-versa are implemented in the binding mechanism. There are some pre-defined validation rules available in the Datatype DSL. As we follow the domain concept to define things as close to the base of the DSL hierarchy as possible, this is the place to go for validations.
For your request, you must define a new datatype as following:
datatype StringNotNull jvmType java.lang.String isNotNull[severity=error]
You can apply a validation rule to every "non-primitive" jvmType (jvm = Java Virtual Machine): Double, Integer..., but not for double, integer... Validation rules are cumulative. The severity of the user response on violation of the rule is definable in 3 flavors:
- info
- warn
- error
Each of them stylable via CSS. The following validation rules are available right now:
- isNotNull
- isNull
- minMaxSize (applies to Strings)
- maxDecimal and minDecimal (applies to Double, Long and Integer - Float is not supported by OS.bee)
- regex (regular expression must be matched - for the advanced designer)
- isPast (applies to date)
- isFuture (applies to date)
► Examples:
datatype DoubleRange jvmType java.lang.Double maxDecimal (10.00) minDecimal (20.00)
datatype String5to8Chars jvmType java.lang.String minMaxSize(5,8)
As a last step you must use the newly created datatype in your entity to let the validation work. There is one additional validation accessible as keyword from the Entity DSL. If you want to enforce the uniqueness of an attribute value like "fullName" you can use the unique keyword in the entity.
► Example:
entity Employee extends BaseID {
persistenceUnit "businessdata"
domainKey unique String fullName
When you are about to save a newly created entry, during bean validation the database is accessed and it is verified, that the given attribute content is not already in the database. Else a validation error with severity error appears in the front-end.
UI-Design
Question:
Is it possible to design a Combo-box/List-box where I can sort the entries by myself? Like in eclipse > Configure Working Sets... Here I ‘m able to select Up / Down to sort the working sets.

In the moment I realize this in the entity with the field listPrio:
entity Title extends BaseUUID {
persistenceUnit "businessdata"
domainKey String
title var
int listPrio
}
Then I sort the entries by giving a value for listPrio. But this is not a good solution.
Answer:
Sorry, not for this time. Sounds useful. I will create a ticket for it.
DSL Dialog: Autosuggestion for DomainKey or DomainDescritpion
Question:
I develop an address management. In the Entity DSL, I have the fields:
domainKey String decription
var String firstname
var String lastname
If I create a user:
firstname: Hans
lastname: Maier
Is it possible to get for the field description automatically suggested the value: Hans-Maier? Like a kind of derived or Operations in Entitiy DSL, but only for suggestion.
Answer:
Yes. After the definition of all attributes, you have the possibility to define methods that can be called by JPA thru annotations.
domainKey String description
...
@PostLoad
def void makeFullName() {
description = firstName+"-"+lastName
}
Remember that decription is completely transient. You could also use @PrePersist or @PreUpdate.
DSL Table
Question:
I have a Table with 100 address data.
Is there a possibility of multi-selection?
► Example of selection of 5 addresses:
- I want to delete in one step 5 addresses.
- I want to send to these 5 addresses the same email.
Answer:
Not for the OSBP version. If you have the BPM option, then the token for BPM can be built using a selectable table. The resulting workload could send emails or deletes against the data base in the following system task.
datamart DSL (condition filtered) table does not refresh
Question:
In a perspective we use organigram / table (user) / dialog (user). The table based on a datamart using the semantic element conditions. Not all position in the organization have assigned user. When a position with assigned user is selected the data rows of the table are filtered. When a position is selected (where no user is assigned) the table does not refresh. What can we change in the model to refresh the table even when there is no corresponding data?
Answer:
DSL authorization (CRUD)
Question:
We tried to authorize the CRUD operations for some position in different ways. All CRUD operations for a given entity "Customer"


Assumpiton:
- For each positon there i a user available
- Each position has an assigned rolte (organization)
- Both user uses the same perspecitve (table/dialog)
- The dialog uses a general toolbar with the necessary actions
Login with user assigned to Position Accounting, create a new datarow (new Customer) and save the data (o.k) Login with user assigned to Position ProjectIntern, select the new Customer in the table, activate delete Button (Row deleted not expected) Is there something to take care about we neglected?
Answer:
DSL Menu(UserFilter/SuperUser)
Question:
When a User marked as SuperUser logged in our Application and the Menu-Modell contains a definition for UserFilter. The Menu is no longer shown inside the application.

The generated Menu in the application looks like this:

If the UserFilter line is included and the application restarted, after login, the application looks like this: (User,Position, and Menu are not visible)

The entity UserAccount and UserAccountFilter have been consider in authorization-DSL with Value ANY assigned to the role used by the user with attribute SuperUser.
Answer:
Printer Selection (Default Printer)
Question:
The Combo-box (Client-Toolbar) for the print-service shows all Printers from the client operating system. The default printer of the operating system is not the preselected for the application. It is possible to define a print-service for each user within the dialog UserAccount? Is it possible for an administrator to select Print-Service for foreign user without having all print-services on his local operating system? Or is it possible to preselect the default print-service insinde the client?
Answer:
DSL Entity Enum with own images
Question:
We tried to create own images for Enum-Values following the document How to add Pictures hosted using URL:
► Example:
enum TypeDocument {
PDF, DOCX }
entity Customer {
persistenceUnit "businessdata"
domainKey String customerKey
id int no
var boolean portalrequired
var String country
var TypeDocument documenttyp }
Own Fragment Bundle
Question:
- There is no hint about image sizes, are there some restrictions?
- There is no preferred way to transfer the created images into the folder (We use Copy and Paste, are there other ways?)
The application started from within Eclipse, Create new data-record using a dialog, the created images are not shown inside the Combo-Box. Can you help me about what went wrong or what is missing?
Answer:
How to synchronize views
Synchronizing tables with dialogs is quite usual for OS.bee. If they share a common entity and they are placed on the same perspective, this is done automatically.
You can now even synchronize tables with reports or tables with tables. They must have an identifier column in common. If so, they are synchronized without the need of a common datamart condition. The receiving view must have the keyword "selectById" on it. Every table emits a selection events of all id columns in the datamart. Not only the id value of the root entity, but also relations emit its id value when displayed in a table and selected.
If you have a datamart of a table with entities related like A->B->C, the selection event emits the values of the selected row of A.id, B.id and C.id. If there is another view on the perspective which uses A, B, or C as root entity, it will automatically synchronized.
There are 2 prerequisites that must match that the receiving view will synchronize automatically:
- the relation of the source view that should work as synchronizing element for the target view must appear as opposite relation in the datamart of the target view.
- the target view's datamart must have at least one normal attribute to show in the associated view.
How to get new features from your toolbar
As you probably know, ActionDSL creates commands, tool items and toolbars. There are some new features that you could use to enhance the usability of your dialog designs. Besides the classic buttons to save, delete, restore or create new entries, there are two new possibilities:
- save and new
- save as new
save and new is quite simple: after saving the dialog will enter the new-entry-mode again and re-uses the previously selected sub-type of the underlying DTO if there was one. The normal save will stay in editing-mode after save was processed.
save as new allows to make copies of the currently selected entry. If there are no uniqueness validations on the dialog, the copy is exactly the same as the previous entry, except for the internally used ID field. If there is a need to create a lot of new entries which are similar to an already existing entry, this button will help reducing time to enter new entries.
![]()
How are these new buttons created?
- create 2 new commands in ActionDSL (you could use your own keybinding shortcut)
command saveAndNew describedBy "save and new" keyBinding "CTRL ALT A" dialogAction SaveAndNew command saveAsNew describedBy "save as" keyBinding "CTRL ALT F" dialogAction SaveAsNew
- add the new commands to your toolbar which is used in your dialogs
toolbar Dialog describedBy "Toolbar for dialogs" items { ... item saveAndNew command saveAndNew icon "dssaveandnew" item saveAsNew command saveAsNew icon "dssaveasnew" ... }
Add user information to your CRUD operations
Sometimes it is desired to have some information persisted concerning the user and the date when an entry was created or modified. This is how this is to be implemented: First you must add the necessary attributes to the entities where this information is needed. If you use a mapped superclass for all entities, it makes it very simple to add it to all entities at once. These attributes must be annotated with the appropriate tag so that the generators know what you want (supply metadata).
Here is an example if using mapped superclasses:
mappedSuperclass BaseUUID {
uuid String id
version int version
@CreateBy
var String createUser
@CreateAt
var Timestamp createAt
@UpdateBy
var String updateUser
@UpdateAt
var Timestamp updateAt
}
The same thing also works for dedicated entities as well. If the EntityDSL inferrer discovers one of the annoations @CreateBy, @CreateAt, @UpdateBy or @UpdateAt it checks the following attribute definition and if the datatype matches the annotation the JPA mechanism will enter the requested information into the new or modified record. So be careful with the datatype, the ...By annotation expect a String to follow, the ...At annotation a Date type.
- How to make it visible to the runtime-user?
You must supply a toolbar command in ActionDSL to enable the user to show the information:
command databaseInfo describedBy "database info" keyBinding "CTRL ALT I" userinterfaceAction Info
Then you must extend your dialog toolbar with the new command:
toolbar Dialog describedBy "Toolbar for dialogs" items {
...
item databaseInfo command databaseInfo icon "dbinfo"
}
You will end up with this toolbar button:

If the user clicks this button or uses its shortcut, a popup window appears showing the requested info. As the user selects different entries and leaves the popup open, its content will refresh according to the underlying information.

Designing dialogs using multiple columns
Generally there are two ways to define dialogs in OS.bee:
- using UI model manually
- using autobinding automatically
The advantage of using UI model is that you can create sophisticated nested layouts and use more than one DTO to bind from even if they don't have a relationship. The disadvantage is that you have to layout and bind manually. If DTO changes, you must also change the depending UI models.
The advantage of using autobinding is that you have nearly nothing to do if your dialog exactly follows the DTO description. A mechanism collects all available metadata from the underlying entities/DTO and tries to render a suitable dialog. The disadvantage is that you can't change layout nor the look.
Except for a new feature in DialogDSL. You can tell the dialog to render a multi-column layout. Just enter the keyword "numColumns" and a number in the dialog grammar.
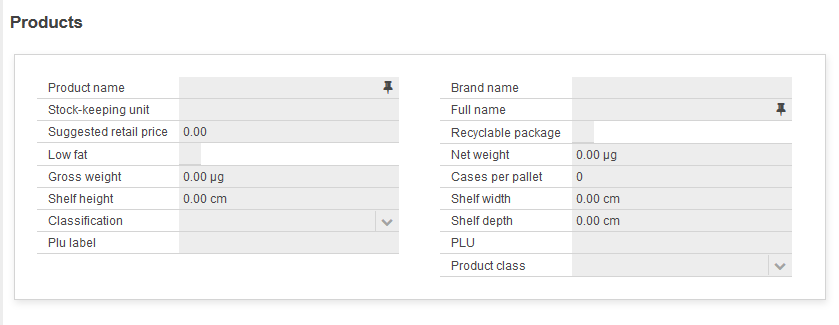
dialog Products describedBy "Products" autobinding MproductDto toolbar Dialog numColumns 2
This will result in a 2-column layout like this:

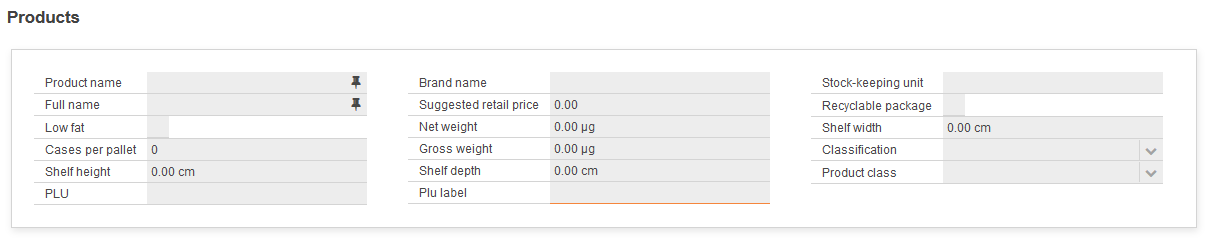
This is how it looks with 3 columns:

Grouping attributes on dialogs
Sometimes there is the need to cluster fields on dialog to logical groups. Thus enforcing readability and better understanding of complex data entry forms (dialogs).
To enable the designer to do so, there is a new keyword "group" followed by an id in the grammar of EntityDSL. The layouting strategy logic of OS.bee finds common ids and collects the attributes together no matter in which order they appear in the entity. The group id cannot have blanks or special characters. The id is automatically added to the i18n properties of EntityDSL in order to be translatable.
Grouped and non-grouped attributes can appear mixed on a dialog. An example for the definition is here:
entity Mproduct_class extends BaseID {
persistenceUnit "businessdata"
domainKey String product_subcategory group category
var String product_category group category
var String product_department group department
var String product_family
ref Mproduct[ * ]products opposite product_class asGrid
}
The dialog is defined like this:
dialog Product_class describedBy "Product Class" autobinding Mproduct_classDto toolbar Dialog numColumns 1
The resulting dialog at runtime look like this:
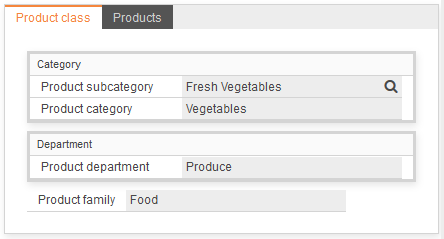

As you can see the field "product family" is not grouped and the one-to-many relationship to products is rendered on a separated tabsheet because the keyword "asGrid" is used for the reference definition.
Here a more complex example for products with a 2-column layout:
entity Mproduct extends BaseID {
persistenceUnit "businessdata"
domainDescription String product_name group category
var String brand_name group category
var String sku group domain
domainKey String fullName group domain
var double srp group sales
var boolean recyclable_package group customerinfo
var boolean low_fat group customerinfo
var MassGRAMMetricCustomDecimal net_weight group logistics
var int units_per_case group logistics
var int cases_per_pallet group logistics
var MassGRAMMetricCustomDecimal gross_weight group logistics
var LengthCMMetricCustomDecimal shelf_width group spacing
var LengthCMMetricCustomDecimal shelf_height group spacing
var LengthMetricCustomDecimal shelf_depth group spacing
var ProductClassification classification group category
var PLUNumber plu group sales
var String pluLabel group sales
ref Mproduct_class product_class opposite products group category
ref Minventory_fact[ * ]inventories opposite product
ref Msales_fact[ * ]sales opposite product
ref CashPosition[ * ]cashPositions opposite product asGrid
@PostLoad
def void makeFullName() {
fullName = sku+"\t"+product_name
}
index sku_index {
sku
}
index plu_index {
plu
}
}
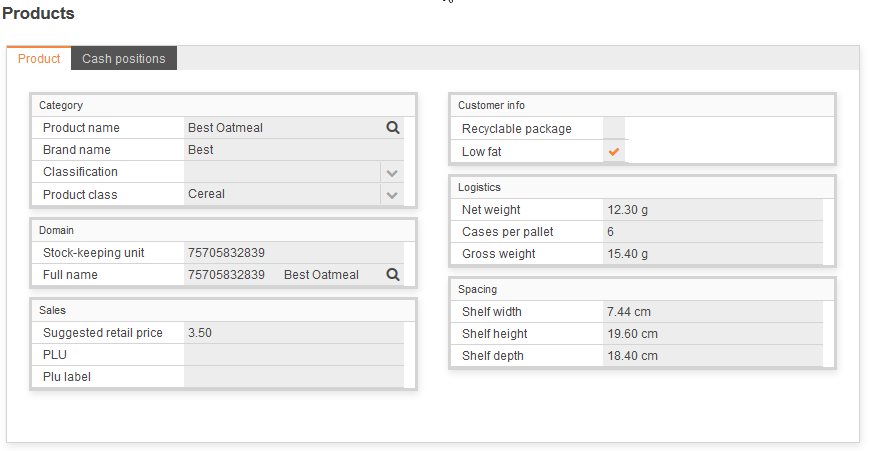

How units of measurements are handled
Often it comes to the situation that a certain value is bound to a unit of measurement. Lengths or masses are common examples. OS.bee supports units of measurement by using a framework called UOMo.
This dialog shows the usage of UOMo in the "Logistics" and "Spacing" group:
If you enter a big value into "Net Weight" for example, the logic will convert it to another unit in the same unit-family:


So there is some business-logic for uom implemented under the hood. When you look at the entity of this attribute, you'll find:
var MassGRAMMetricCustomDecimal net_weight group logistics
and in DatatypeDSL it look like this:
datatype MassGRAMMetricCustomDecimal jvmType java.lang.Double asPrimitive
properties (
key="functionConverter" value="net.osbee.sample.foodmart.functionlibraries.UomoGRAMMetricConverter"
)
So what you can see is that the basic type is Double and a converter handles the uom stuff. Let's look at the FunctionLibraryDSL for this definition:
converter UomoGRAMMetricConverter {
model-datatype Double presentation-datatype BaseAmount
to-model {
var localUnitFormat = LocalUnitFormatImpl.getInstance( presentationLocale );
var baseUnit = localUnitFormat.format( MetricMassUnit.G ) var suffix =( presentationParams.get( 1 ) as String ) if( suffix === null ) {
suffix = baseUnit
}
if( localUnitFormat.format( MetricMassUnit.KG ).equals( suffix ) ) {
var amount = MetricMassUnit.amount( presentationValue, MetricMassUnit.KG ) return amount.to( MetricMassUnit.G ).value.doubleValue
}
else if( localUnitFormat.format( MetricMassUnit.MG ).equals( suffix ) ) {
var amount = MetricMassUnit.amount( presentationValue, MetricMassUnit.MG ) return amount.to( MetricMassUnit.G ).value.doubleValue
}
else {
return presentationValue
}
}
to-presentation {
var amount = MetricMassUnit.amount( modelValue, MetricMassUnit.G ) if( modelValue > 1000d ) {
amount = amount.to( MetricMassUnit.KG )
}
else if( modelValue < 1d ) {
amount = amount.to( MetricMassUnit.MG )
}
return amount as BaseAmount
}
}
You discover for this function a logic separated in two parts:
- to-model
- to-presentation
As the function must provide a logic to convert database values to the UI (presentation), and after the user changed a value, back to the database (model), it has two parts. The 2. part is called the inverse function. Each part tries to find the most suitable unit for the given value. The base-unit is defined as metric gramm and all other values stay in the same family. As a result the value is stored in base-units.
While you play around with units of measurement you'll find out that you could easily build converters between families but also to convert from imperial unit systems to metric (SI=Système international d'unités ) and vice versa.
How sliders can improve the user experience with your dialogs
Sliders are well known to adjust analogue values in the world of audio.


If you want to use a similar technology to let your user adjust values in an analogue manner, you can use sliders. Just define a new datatype based on a numeric primitive type and supply it with the minimum and maximum values for the adjustable range.
datatype Slider_1000_2000 jvmType int
properties(
key="type" value="slider",
key="min" value="1000",
key="max" value="2000"
)
Use the new datatype in an entity:
var Slider_1000_2000 slideDelay
The resulting dialog looks like this:
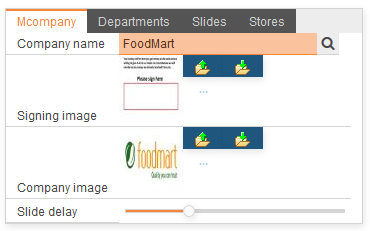

It looks kindof more convenient instead of entering a number between 1000 and 2000.
New ways to supply icons for enum literals
Icons are now automatically generated when the entity model is generated. In every location of entity models a folder "enums" will be created and one sub-folder for each type of enumeration. Every literal of the enum will create a png-file with size 1x1 white pixel. This makes it easy to supply a custom icon for every enum literal located near the definition. You just copy a 16x16 pxel sized png file over the generated one. There is no need to suppress icons if no icons are needed as they are invisible when generated 1x1 pixel sized.
After generation the folders look like:
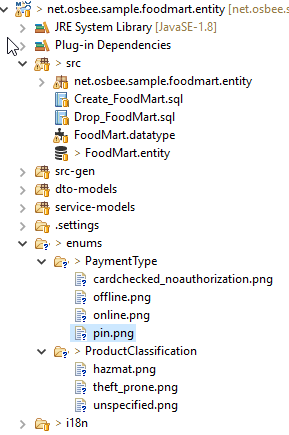

After you have overridden the icons, the combo box looks like this:
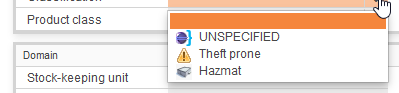
IMPORTANT: you must modify your build.properties like described here.
Validation
If you deal with storing data for later usage, you'll be confronted with the fact that users or imports sometimes enter data that could be invalid for later processing. To avoid these problems you must validate data before it is stored. The necessity of a generic validation upon bean-data was detected in 2009 and the JSR303 was created. Built on this specification Apache created a framework to fullfil the specification BeanValidation.
OS.bee exploits this framework and grants access to some validation annotations by using a grammar extension in DatatypeDSL and EntityDSL. Therefore a kind of business logic is implemented by using validations. Naturally validation keywords are datatype specific and not all can be used everywhere.
The violation of a validation can be signalled to the user in 3 different levels of severity:
- INFO
- WARN
- ERROR
where only ERROR prevents data from saving to database.
The following validations per datatype can be used (either in DatatypeDSL or in EntityDSL):
- For all datatypes
- isNull invalid if value was set
- isNotNull invalid if value was never set
- Boolean
- isFalse invalid if value is true
- isTrue invalid if value is false
- Date/Time/Timestamp
- isPast invalid if date lies in the past in reference of today
- isFuture invalid if date lies in the future in reference of today
- Decimal (1.1, 1.12 ...)
- maxDecimal invalid if decimal exceeds the given value
- minDecimal invalid if decimal underruns the given value
- digits invalid if decimal has more digits or more fraction digits than the given 2 values
- regex invalid if the value does not match the given regular expression
- Numeric (1, 2, ...)
- maxNumber invalid if number exceeds the given value
- minNumber invalid if number underruns the given value
- minMaxSize invalid if number is not in the given range of 2 values
- regex invalid if the value does not match the given regular expression
- String
- regex invalid if the value does not match the given regular expression
The messages prompted to the user come in a localized form out of the Apache framework.
An example for a regular expression is this:
var String[ regex( "M|F" [severity=error]) ]gender
Here an example for a date validation:
datatype BirthDate dateType date isNotNull isPast[severity=error]
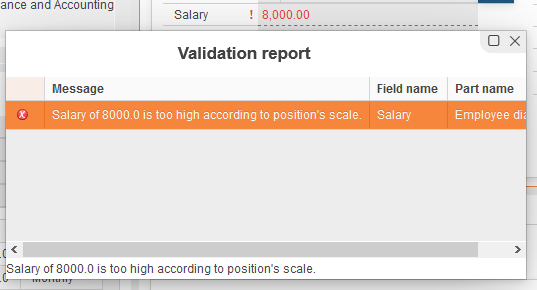
The violation of this rule looks like this:
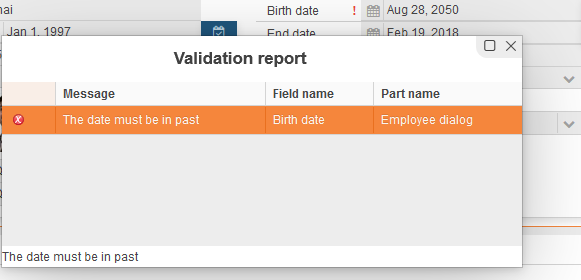

If you point at the exclamation mark beside this field after closing the Validation report you will see:


For EntityDSL there is an extra keyword to validate if an entry is already in the database or not. You can use it if you want unique entries in a certain field.
domainKey unique String full_name
If there is a violation of this rule, the dialog looks like this:


This also works for normal fields that are not domainKeys.
Extended Validation
To enforce business rules can be a sophisticated task for traditional software projects. With OS.bee it is possible to create a DTO validation with the FunctionLibraryDSL with less effort. As DTO build up dialogs in autobinded mode, you get a dialog validator for free.
These are the steps to create one:
- create a validation group in the FunctionLibraryDSL and name it like the DTO that you want to validate followed by the token Validations:
validation MemployeeDtoValidations { ... }
- MemployeeDto would be the DTO to validate.
- create inside the named validation group methods that should be processed every time a save button on a dialog is pressed or validate is called from somewhere else:
validate highSalary(Object clazz, Map<String, Object> properties) { ... }
- In clazz the DTO to validate is given. You could access data that is related to this DTO to validate e.g. the max salary allowed like this:
var dto = clazz as MemployeeDto if(dto.salary > dto.position.max_scale) { ... }
The properties map can be used to get some contextual information and services.
properties.get("viewcontext.service.provider.thirdparty")
gives access to the EclipseContext and therefore to a lot of services registrated there. Use the debugger to get more information.
var map = properties.get("viewcontext.services") as Map<String,Object>
var user = map.get("org.eclipse.osbp.ui.api.user.IUser") as IUser
gives access to the current user's data. To distinct the validation for a certain user role, you could use this code:
if(!user.roles.contains("Sales")) { ... }
Every validate method must return either null if there is no validation rule violated or a Status. The Status is created as following:
var status = Status.createStatus("", null, IStatus.Severity.ERROR, "salaryTooHigh", dto.salary)
where the first 2 parameters are optional and not explained here. The 3. parameter selects severity (here: error). The 4. parameter is the translation key for the properties file and the last parameter is an optional value that could be integrated into the translated message. Remember that all translation keys are decomposed into lowercase keys with underscores for compatibility reasons. So the key "salaryTooHigh" results in a key "salary_too_high". You could than create a translation like this:
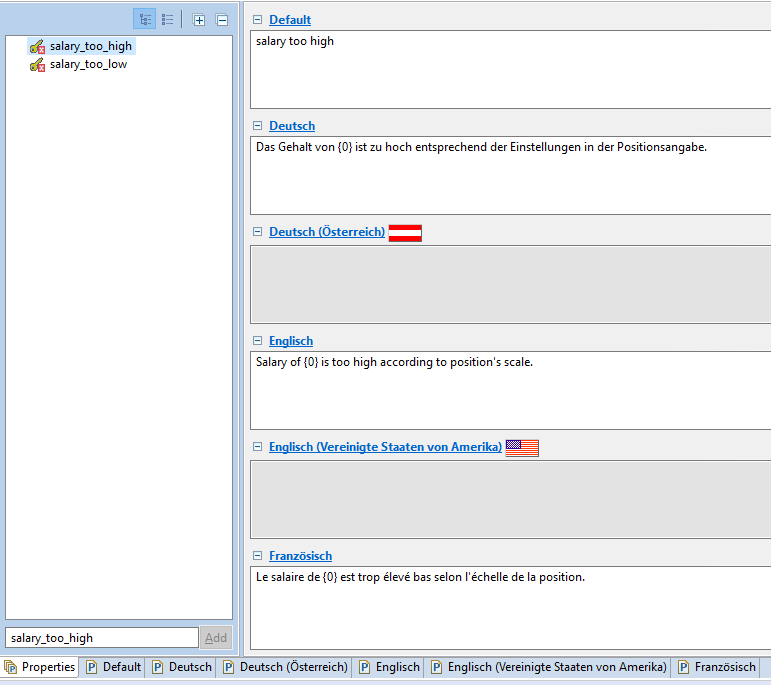

{0} works as placeholder where the last parameter is inset. The appropriate message looks like this in the dialog:

So, the complete code for the business rule: "Salaries must be in a range defined by the employee's position record and can't be violated except for users with the role "Sales" who can exceed the upper limit but not below the lower limit." looks like this:
validation MemployeeDtoValidations {
validate highSalary(Object clazz, Map<String, Object> properties) {
var dto = clazz as MemployeeDto
if(dto.salary > dto.position.max_scale) {
var map = properties.get("viewcontext.services") as Map<String,Object>
var user = map.get("org.eclipse.osbp.ui.api.user.IUser") as IUser
var IStatus status
if(user.roles.contains("Sales")) {
status = Status.createStatus("", null, IStatus.Severity.ERROR, "salaryTooHigh", dto.salary)
}
status.putProperty(IStatus.PROP_JAVAX_PROPERTY_PATH, "salary");
return status
}
return null
}
validate lowSalary(Object clazz, Map<String, Object> properties) {
var dto = clazz as MemployeeDto
if(dto.salary < dto.position.min_scale) {
var status = Status.createStatus("", null, IStatus.Severity.ERROR, "salaryTooLow", dto.salary)
status.putProperty(IStatus.PROP_JAVAX_PROPERTY_PATH, "salary");
return status
}
return null
}
}
Reset cached data
In order to provide a responsive and modifiable user interface, some data is cached while some data is stored to the database. In case you need to reset this data, there is a new keyword in MenuDSL to provide a small dialog where this can be done.
category Settings systemSettings
If you have done so, the resulting menu will look like this:
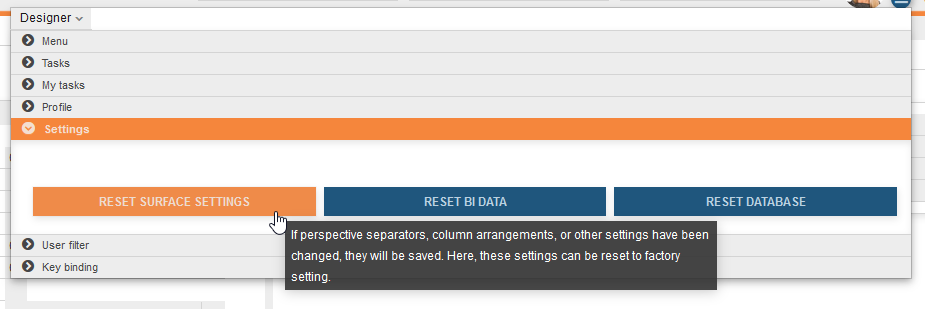

The tooltip will provide additional information about what can be reset here. For the moment there are 3 option:
- reset surface settings
- modifications done by the current user during runtime are stored and restored with the next usage of the application. Modifications comprise
- splitter positions in perspectives
- column order in tables
- column width in tables
- column hiding intables
- reset BI data
- the underlying framework for BI data is Mondrian that makes heavy use of caches for cube related data. Whenever data changes through the use of external tools, the cache will not be reset automatically. This can be done here.
- reset database
- the underlying framework JPA als makes use of caches. For the same reason as with Mondrian, its cache can be reset here.
Therefore, it is no longer needed to restart the application server if data was changed by SQLDeveloper or TOAD or similar tools, just press reset caches here. And, if you are unsatisfied with your private settings for the surface, reset it here to factory settings.
WARNING: If you press "reset database" or "reset BI", the reset comprises the whole application with all currently connected sessions and users. BI analytics and database access will react delayed until all caches are rebuilt.
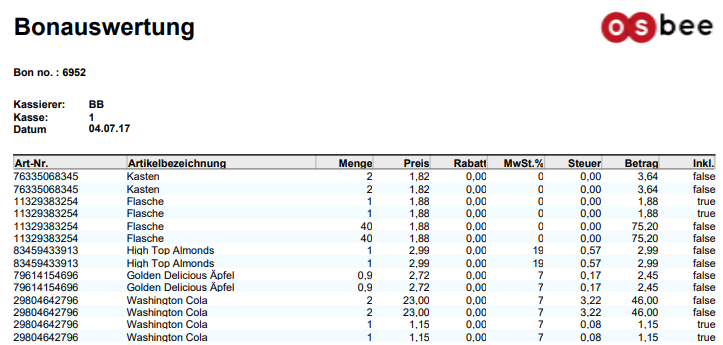
ReportDSL: How to get a checkbox for a Boolean attribute
The common outputs for a boolean attribute are the strings "true" or "false". As you can see in the following report using the attribute:
entity CashPosition ... {
...
var boolean taxIncluded
...
}

But enhancing the attribute with the property "checkbox" as shown here:
entity CashPosition ... {
...
var boolean taxIncluded properties ( key = "checkbox" value = "" )
...
}
the report output for the same boolean attribute is like this:
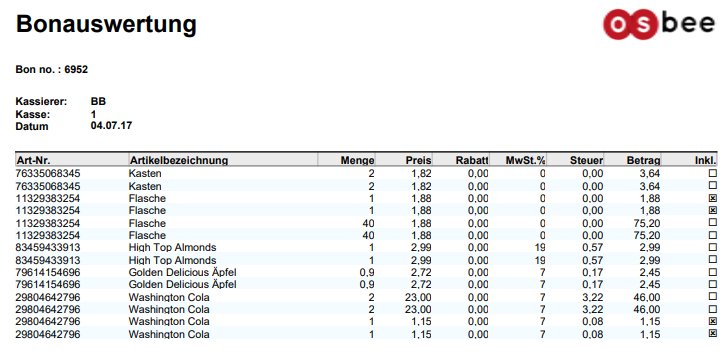

How to collect business data and presenting meaningful statistics with OS.bee - INTRODUCTION
Before one can present and interpret information, there has to be a process of gathering and sorting data. Just as trees are the raw material from which paper is produced, so too, can data be viewed as the raw material from which information is obtained.
In fact, a good definition of data is "facts or figures from which conclusions can be drawn".
Data can take various forms, but are often numerical. As such, data can relate to an enormous variety of aspects, for example:
- the daily weight measurements of each individual in a region
- the number of movie rentals per month for each household
- the city's hourly temperature for a one-week period
Once data have been collected and processed, they are ready to be organized into information. Indeed, it is hard to imagine reasons for collecting data other than to provide information. This information leads to knowledge about issues, and helps individuals and groups make informed decisions.
Statistics represent a common method of presenting information. In general, statistics relate to numerical data, and can refer to the science of dealing with the numerical data itself. Above all, statistics aim to provide useful information by means of numbers.
Therefore, a good definition of statistics' is "a type of information obtained through mathematical operations on numerical data".
| Information | Statistics |
|---|---|
| the number of persons in a group in each weight category (20 to 25 kg, 26 to 30 kg, etc.) | the average weight of colleages in your company |
| the total number of households that did not rent a movie during the last month | the minimum number of rentals your household had to make to be in the top 5% of renters for the last month |
| the number of days during the week where the temperature went above 20°C | the minimum and maximum temperature observed each day of the week |
Business analysis is the term used to describe visualizing data in a multidimensional manner. Query and report data typically is presented in row after row of two-dimensional data. The first dimension is the headings for the data columns and the second dimension is the actual data listed below those column headings, called the measures. Business analysis allows the user to plot data in row and column coordinates to further understand the intersecting points. But more than 2 dimensions usually apply to business data. You could analyze data along coordinates as time, geography, classification, person, position and many more.
OS.bee is designed for Online analytical processing (OLAP) using a multidimensional data model, allowing for complex analytical and ad hoc queries with a rapid execution time. Typical applications of OLAP include business reporting for sales, marketing, management reporting, business process management (BPM), budgeting and forecasting, financial reporting and similar areas.
Study this excellent guide for a deeper understanding of cubes, dimensions, hierarchies and measures:Beginner's guide to OLAP .
How to collect business data and presenting meaningful statistics with OS.bee – PART1
The storage and retrieval containers
In a nutshell:
- we store data using entities and relationships
- we retrieve information using cubes and dimensions.
Storage with entities
The backbone of statistics is a container for quantitative facts. In this tutorial we want to create statistical data upon cash-register sales. We call the container for these facts "SalesFact". It inherits from BaseUUID therefore providing a primary key and some database information and saves data within the persistence unit "businessdata":
entity SalesFact extends BaseUUID {
persistenceUnit "businessdata"
/* actual net revenue */
var double sales
/* net costs of the goods and costs for storage */
var double costs
/* quantity of goods sold */
var double units
}
Leaving the container as is we could aggregate some measurements but we have no idea of when, where and what was sold. So we need additional information related to this event of sale. We call it a coordinate system for measures or just a dimension.
entity SalesFact extends BaseUUID {
persistenceUnit "businessdata"
/* actual net revenue */
var double sales
/* net costs of the goods and costs for storage */
var double costs
/* quantity of goods sold */
var double units
/* what product was sold */
ref Mproduct product opposite salesFact
/* when was it sold */
ref MtimeByDay thattime opposite salesFact
/* to whom it was sold */
ref Mcustomer customer opposite salesFact
/* was it sold during a promotional campaign */
ref Mpromotion promotion opposite salesFact
/* where was it sold */
ref Mstore store opposite salesFact
/* which slip positions were aggregated to this measure (one to many relationship) */
ref CashPosition[ * ]cashPositions opposite salesFact
/* which cash-register created the sale */
ref CashRegister register opposite salesFact
}
Please don't forget to supply the opposite sides of the reference (relation) with the backward's references:
ref SalesFact[ * ]salesFact opposite product
...
ref SalesFact[ * ]salesFact opposite thattime
...
ref SalesFact[ * ]salesFact opposite customer
...
ref SalesFact[ * ]salesFact opposite promotion
...
ref SalesFact[ * ]salesFact opposite store
...
ref SalesFact[*] salesFact opposite register
...
ref SalesFact salesFact opposite cashPositions
Let's have a look at a very special container, the time. The date attribute is not enough. You must amend some additional information and therefore functionality so it becomes a usable dimension:
entity MtimeByDay extends BaseID {
persistenceUnit "businessdata"
var Date theDate
var String theDay
var String theMonth
var String theYear
var String theWeek
var int dayOfMonth
var int weekOfYear
var int monthOfYear
var String quarter
ref SalesFact[ * ]salesFact opposite thattime
@PrePersist
def void onPersist() {
var dt = new DateTime(theDate)
theDay = dt.dayOfWeek().asText
theWeek = dt.weekOfWeekyear().asText
theMonth = dt.monthOfYear().asText
theYear = dt.year().asText
weekOfYear = dt.weekOfWeekyear().get
dayOfMonth = dt.dayOfMonth().get
monthOfYear = dt.monthOfYear().get
quarter = 'Q'+((month_of_year/3)+01)
}
index byTheDate {
theDate
}
}
As you can see from the code, the given date "theDate" is used to calculate other values that are useful for retrieving aggregates of measures using a dimension like time with the level "quarter" or "theYear". If we want to use a "Timeline" as dimension for statistics from OLAP, we also need to create an entry and a relation to the MtimeByDay entity.
How are these calculations invoked?
Due to the annotation @PrePersist at the method declaration of "onPersist", JPA calls this method every time before a new entry in MtyimeByDay is inserted. Be careful inside these methods: if an exception is thrown due to sloppy programming (e.g. null pointer exception), nothing in the method will be evaluated. Here are the other entities we need later:
entity ProductClass extends BaseUUID {
persistenceUnit "businessdata"
domainKey String productSubcategory
var String productCategory
var String productDepartment
var String productFamily
ref Mproduct[ * ]products opposite productClass
}
entity Product extends BaseUUID {
persistenceUnit "businessdata"
domainKey String productName
var String brandName
var String sku
var double srp
var boolean recyclablePackage
var boolean lowFat
ref ProductClass productClass opposite products
ref InventoryFact[ * ]inventories opposite product
ref SalesFact[ * ]salesFact opposite product
ref CashPosition[ * ]cashPositions opposite product
}
entity Customer extends BaseUUID {
persistenceUnit "businessdata"
var String maritalStatus
var String yearlyIncome
var String education
ref SalesFact[ * ]salesFact opposite customer
ref CashSlip[ * ]slips opposite customer
}
entity Promotion extends BaseUUID {
persistenceUnit "businessdata"
domainKey String promotion_name
var String mediaType
var double cost
var Date startDate
var Date endDate
ref SalesFact[ * ]salesFact opposite promotion
}
entity Store extends BaseUUID {
persistenceUnit "businessdata"
domainKey String storeName
var int storeNumber
var String storeType
var String storeCity
var String storeStreetAddress
var String storeState
var String storePostalCode
var String storeCountry
var String storeManager
var String storePhone
var String storeFax
ref InventoryFact[ * ]inventories opposite store
ref SalesFact[ * ]salesFact opposite store
ref CashRegister[ * ]registers opposite store
}
entity InventoryFact extends BaseUUID {
persistenceUnit "businessdata"
var int unitsOrdered
var int unitsShipped
var int supplyTime
var double storeInvoice
ref Product product opposite inventories
ref TimeByDay thattime opposite inventories
ref Store store opposite inventories
}
entity CashRegister extends BaseUUID {
persistenceUnit "businessdata"
domainKey unique String num
var unique String ip
var unique String location
var Date currentDay
ref CashSlip[*]slips opposite register
ref Store store opposite registers
ref SalesFact[*] salesFact opposite register
}
entity CashSlip extends BaseUUID {
persistenceUnit "businessdata"
var Date currentDay
var Timestamp now
var String cashier
var Price total
@ GeneratedValue var long serial
var boolean payed
var boolean posted
ref CashPosition[ * ]positions opposite slip
ref Customer customer opposite slips
ref CashRegister register opposite slips
}
entity CashPosition extends BaseUUID {
persistenceUnit "businessdata"
var Timestamp now
var double quantity
var Price price
var Price amount
ref CashSlip slip opposite positions
ref Product product opposite cashPositions
ref SalesFact salesFact opposite cashPositions
}
The mapped superclass from which all entities inherit is this:
mappedSuperclass BaseUUID {
uuid String id
version int version
}
How to collect business data and presenting meaningful statistics with OS.bee – PART2
Retrieval with MDX
The framework used to retrieve OLAP data is Mondrian from Pentaho. You'll find a complete documentation with this link. The language to retrieve multi-dimensional data was originally defined by Microsoft and an introduction to the MDX languge can be found there. For the moment not all features of Mondrian are implemented yet. E.g. among others: properties of levels, inline tables, functional dependency and other optimizations, and virtual cubes.
Dimensions
These dimensions presuppose that you already defined the appropriate entities and data inside.
At what point in time was the sale?
In Cube DSL I define the time dimension as following:
dimension TheTime typeTime {
hierarchy hasAll allMemberName "All Times" {
entity TimeByDay {
level Year column theYear uniqueMembers levelType TimeYears
level Month column monthOfYear levelType TimeMonths
level Day column dayOfMonth levelType TimeDays
}
}
hierarchy Quarterly hasAll allMemberName "All Times" {
entity TimeByDay {
level Year column theYear uniqueMembers levelType TimeYears
level Quarter column quarter levelType TimeQuarters
level Month column monthOfYear levelType TimeMonths
level Day column dayOfMonth levelType TimeDays
}
}
hierarchy Weekly hasAll allMemberName "All Times" {
entity TimeByDay {
level Year column theYear uniqueMembers levelType TimeYears
level Week column weekOfYear levelType TimeWeeks
level Day column dayOfMonth levelType TimeDays
}
}
}
The time dimension consists of several hierarchies. The reason for this is that weeks don't align to month boundaries. Therefore there is no real hierachical structure in this combination. The solution to this is to seperate the dimension in several hierarchies. If a hierarchy has no name by its own, the name is identical to the dimension's name. It is not necessary to define hierarchies but they are very common for many business cases.
Each hierarchy consists of one or more levels of aggregation. The levels should be sorted from the most general to the most specific. Levels have relationships with one another. A day has 24 hours, an hour has 60 minutes, and a minute has 60 seconds. When the levels are organized in order to represent their relationship with one another, a hierarchy is formed. If a measure is stored by using the time in seconds, the cube is able to return all aggregates of this measure per minute, per hour and day. It is not possible to synthesize the more specific level though. This is true for all dimensions, hierarchies and their levels. Levels link to attributes of entities. Best for performance is a so called "star schema" where all levels are united into one entity. The other way is a "snowflake schema" where levels are to be evaluated by navigation through may-to-one relationships. For Mondrian, there is only one level up allowed.
Special for all time related dimensions is that the levels must be classified with an extra keyword to describe the type (TimeYears, TimeMonths, TimeDays, etc.).
Where was the sale?
The dimension for "Store" looks like this:
dimension Store {
hierarchy hasAll allMemberName "All Stores" {
entity Store {
level StoreCountry column storeCountry uniqueMembers
level StoreState column storeState uniqueMembers
level StoreCity column storeCity
level StoreName column storeName uniqueMembers
}
}
}
Best practice for levels is to provide the keyword hasAll together with the allMembername. Doing so will enable you to leave the dimension completely by using the "allMember" aggregate or to use the "Children" (Mondrian) function by using the "detailed" keyword in Datamart DSL. The uniqueMembers attribute is used to optimize SQL generation. If you know that the values of a given level column in the dimension table are unique across all the other values in that column across the parent levels, then set uniqueMembers="true", otherwise, set to "false". For example, a time dimension like [Year].[Month] will have uniqueMembers="false" at the Month level, as the same month appears in different years. On the other hand, if you had a [Product Class].[Product Name] hierarchy, and you were sure that [Product Name] was unique, then you can set uniqueMembers="true". If you are not sure, then always set uniqueMembers="false". At the top level, this will always be uniqueMembers="true", as there is no parent level.
What was the sale about?
Here is the "Product" dimension:
dimension Product {
hierarchy hasAll allMemberName "All Products" {
entity Product {
level ProductName column productName uniqueMembers
entity ProductClass {
over productClass
level ProductFamily column productFamily uniqueMembers
level ProductDepartment column productDepartment
level ProductCategory column productCategory
level ProductSubcategory column productSubcategory
}
}
}
}
Was the sale inside a promotional period?
And the "Promotions" dimension:
dimension Promotions {
hierarchy hasAll allMemberName "All Promotions" {
entity Promotion {
level PromotionName column promotionName uniqueMembers
}
}
}
Who was the customer of this sale?
At last the "Customers" dimensions:
dimension Customers {
hierarchy hasAll allMemberName "All Customers" {
entity Customer {
level Country column country uniqueMembers
level StateProvince column stateProvince uniqueMembers
level City column city
}
}
}
dimension EducationLevel {
hierarchy hasAll allMemberName "All Grades" {
entity Customer {
level EducationLevel column education uniqueMembers
}
}
}
dimension MaritalStatus {
hierarchy hasAll allMemberName "All Marital Status" {
entity Customer {
level MaritalStatus column maritalStatus uniqueMembers
}
}
}
dimension YearlyIncome {
hierarchy hasAll allMemberName "All Incomes" {
entity Customer {
level YearlyIncome column yearlyIncome uniqueMembers
}
}
}
With the last dimensions: "Education Level, Marital Status and Yearly Income" you can classify the sale in detail and draw conclusions what group of costumers is the most likely to buy a certain product class.
How to collect business data and presenting meaningful statistics with OS.bee – PART3
Putting data inside the storage entities
As mentioned in a previous entry, I cannot supply necessary data for all entities that will be referenced to build up dimensions. Also, it is assumed that you have some valid inventory-facts data and sales in your cash-register entities.
In this entry I explain how to collect and enrich data from multiple sources and to insert them using the batch-writing mechanism from JPA. It is vital to your application's OLAP performance to concentrate statistical data to a single entity per topic and cube. The resulting code can be executed manually or in a timer-scheduled manner.
First of all you must define a new "action" in your FunctionLibrary DSL file. In this case we want to create a button on the cashregister dialog that, once pressed, will post all sales in the statistical entity and change the current cash-register day to today. For every action class 2 methods must be defined:
- canExecute
this function is invoked by OS.bee to decide the state of the toolbar button: active (method returns true) or disabled (method returns false).
- execute
this method holds the code that shall be executed when the enabled button is pressed.
action CashNewDay {
canExecute canChangeDay( IEclipseContext context ) {
return true
}
execute doNewDay( IEclipseContext context ) {
}
Be sure to have IEclipseContext as parameter for both methods, as we will need them later on.
How to collect business data and presenting meaningful statistics with OS.bee – PART4
Use MDX to generate statistics
If you reach this part, all needed containers have been defined and filled with data in order to enable business analysis as described in this part. Retrieval of data is defined with Datamart DSL. Datamart DSL eases the way you can define queries and mdx statements.
Let's say you have the following requirement:
show aggregated sales and costs in a table and a diagram of the top 10 products in sales amount by selecting a month and one or many product categories
How would you solve the requirement with sql? This wouldn't be easy. With MDX you can use powerful aggregators that will help you to solve the requirement with just a few words. The correct syntax would be (the part inside [ ] shows where the selected values have to be inserted):
select Non Empty{[Measures].[StoreSales],[Measures].[StoreCost]} on columns,
Non Empty TOPCOUNT([Product].[ProductCategory],10,[Measures].[StoreSales])
on rows from Sales where ([TheTime].[Month])
The parameter [TheTime].[Month] for example must be replaced by [1997].[3]. This syntactical element is called a slicer because it makes a slice through the cube only showing filtered aspects according to that slice.
With the help of Datamart DSL, the model code looks like this:
datamart SalesTop10ProductTime using cube Sales nonempty {
axis columns {
measure StoreSales
measure StoreCost
}
axis rows {
topcount( 10 ) of hierarchy Product level ProductCategory selected detailed over measure StoreSales
}
slicer hierarchy TheTime level Month filtered
}
The model contains more keywords than the real MDX but for the sake of simplyfication. And the DSL guides through all possible keywords and references avoiding the error prone process of formulating a correct MDX statement. You can try to enter a MDX statement directly into OS.bee. You can press STRG-ALT+M if a part has the current focus. A dialog pops up with a prepared and valid MDX statement to test connectivity and you can experiment with MDX here.

If you want to show the result of the datamart result in a table, you can enter the following model phrase in Table DSL:
table SalesTop10ProductTime describedBy "salesTop10Product" as readOnly filtering rowHeader indexed
using datamart SalesTop10ProductTime
The table renders like this:

Let's make a diagram out of these results using Chart DSL. The model phrase looks like this:
chart SalesTop10ProductTime describedBy "salesTop10Product" as bar
animated shaded using datamart SalesTop10ProductTime {
axis columns renders linear
axis rows renders category shortLabel angle 90
legend inside toggle replot fast
tooltip north-west inside
}
The keyword "angle" rotates tick labels by the given value in degrees.
This is how the chart will looks like:

Another requirement against the same cube could sound like this:
Show aggregated sales and costs in a table and a diagram splitted by sales regions and product departments by selecting a month. Some selectable product departments must be excepted from displaying. The exception list must be long enough to see all product departments.
The new requirement requires a multi-dimensional view on information. The datamart model looks similar than the example before except for a new axis representing the extra dimension and the exception filter:
datamart SalesByProductDepartmentRegionTime showFilterCaptions numberOfMultiSelectionRows 30 using cube Sales {
axis columns {
measure StoreSales
measure StoreCost
}
axis rows {
hierarchy Product level ProductDepartment except ProductDepartment
}
axis pages {
hierarchy Geography level Region
}
slicer hierarchy TheTime level Month filtered
}
Axes with increasing dimension are named like this: columns, rows, pages, chapters and sections. For the moment, the number of dimensions to be displayed simultaneously is limited to 5. The keyword "showFilterCaptions" displays a label for the selector additionally to the tooltip, whereas "numberOfMultiSelectionRows" followed by a number widens the list to the number of entries given.
The table's model phrase looks like this:
table SalesByProductDepartmentRegionTime describedBy "salesByProductDepartment" as readOnly filtering rowHeader indexed using datamart SalesByProductDepartmentRegionTime
The "indexed" keyword adds a column to show the original sorting from the cube.

The chart's model phrase is this:
chart SalesByProductDepartmentRegionTime describedBy "salesByProductDepartment" as bar
animated swapped using datamart SalesByProductDepartmentRegionTime {
axis columns renders linear
axis rows renders category shortLabel
legend inside toggle replot fast
tooltip north-west inside
}
The keyword "shortLabel" helps to keep the chart clear: it suppresses the long description of dimension level and only shows the last level instead of all supplemental levels above. But there could be reasons to show the fully qualified level-name at the category axis. The keyword "swapped" swaps the x-axis with the y-axis. By clicking on an entry from the legend, you can toggle the data series. This is enabled by "toggle".

As you can see, all "Food" departments are removed from the chart.
Surrogate or natural keys in entity models?
Nearly every day in my work I'm confronted with the question:
Wouldn't it be better to use the natural key (domain key) than a synthetical UUID (GUID) or a generated number?'
I found this excellent article that explains in detail the pros and cons: Surrogate or natural key: How to make the right decision
- The superiority of surrogate keys compared to natural keys is a much debated issue among database developers. ZDNet provides tips on when and why which type of key should be preferred.
- by Susan Harkins on May 19, 2011, 4:00 pm
According to relational database theory, a correctly normalized table must have a primary key. However, database developers are arguing over whether surrogate keys or natural keys are better. Data contains a natural key. A surrogate key is a meaningless value that is usually generated by the system. Some developers use both types of keys, depending on the application and data, while others strictly adhere to a key type.
The following tips mostly prefer surrogate keys (as the author does), but there should be no stiffening on a key type. It is best to be practical, reasonable and realistic and to use the key that suits you best. However, every developer should keep in mind that he chooses to make a long-term choice, which affects others as well.
- A primary key must be unique
- A primary key uniquely identifies each entry in a table and links the entries to other data stored in other tables. A natural key may require multiple fields to create a unique identity for each entry. A surrogate key is already unique.
- The primary key should be as compact as possible
- In this case, compact means that not too many fields should be required to uniquely identify each entry. To obtain reliable data, multiple fields may be required. Developers who think natural keys are better often point out that using a primary key with multiple fields is no more difficult than working with a single-field primary key. In fact, it can be quite simple at times, but it can also make you desperate.
- A primary key should be compact and contain as few fields as possible. A natural key may require many fields. A surrogate key requires only one field.
- There can be natural keys with only one field
- Sometimes data has a primary key with only one field. Company codes, part numbers, seminar numbersand ISO standardized articles are examples of this. In these cases, adding a surrogate key may seem superfluous, but you should weigh your final decision carefully. Even if the data seems stable for the moment, appearances can be deceptive. Data and rules change (see point 4).
- Primary key values should be stable
- A primary key must be stable. The value of a primary key should not be changed. Unfortunately, data is not stable. In addition, natural data is subject to business rules and other influences beyond the control of the developer. Developers know and accept that.
- A surrogate key is a meaningless value without any relationship to the data, so there is no reason to ever change it. So when you're forced to change the value of a surrogate key, it means something has been wronged.
- Know the value of the primary key to create the entry
- The value of a primary key can never be zero. This means knowing the value of the primary key to create an entry. Should an entry be created before the value of the primary key is known? In theory, the answer to this is no. However, practice sometimes forces one to do so.
- The system creates surrogate key values when a new entry is created so that the value of the primary key exists as soon as the entry exists.
- No duplicate entries are allowed
- A normalized table can not contain duplicate entries. Although this is possible from a mechanical point of view, it contradicts relational theory. Also, a primary key can not contain duplicate values, with a unique index preventing duplicate values. These two rules complement each other and are often cited as arguments for natural keys. The proponents of natural keys point out that a surrogate key allows for duplicate entries. If you want to use a surrogate primary key, just apply an index to the corresponding fields and the problem is solved.
- Users want to see the primary key
- There is a misunderstanding about the user's need to know the value of the primary key. There is no reason, theoretical or otherwise, for users to see the primary key value of an entry. In fact, users do not even need to know that such a value exists. It is active in the background and has no meaning to the user as he enters and updates this data, runs reports, and so on. There is no need to map the primary key value to the entry itself. Once you've got rid of the idea that users need the primary key value, you're more open to using a surrogate key.
- Surrogate keys add an unnecessary field
- Using a surrogate key requires an extra field, which some consider a waste of space. Ultimately, everything needed to uniquely identify the entry and associate it with data in other tables already exists in the entry. So why add an extra column of data to accomplish what the data alone can do?
- The cost of a self-generating value field is minimal and requires no maintenance. Taken alone, this is not a sufficient reason for recommending a natural key, but it is a good argument.
- Do not systems make mistakes?
- Not everyone trusts system-generated values. Systems can make mistakes. This basically never happens, but it is theoretically possible. On the other hand, a system susceptible to this type of disturbance can also have problems of natural value. To be clear, the best way to protect a complete database, not just the primary key values, is to make regular backups of it. Natural data is also no more reliable than a system-generated value.
- Some circumstances seem to require a natural key
- The only reason a natural key might be required is for integrated system entries. In other words, sometimes applications that share similar tables create new entries independently. If you do not make any arrangements, the two databases will probably generate the same values. A natural key in this case would prevent any duplicate primary key values.
- There are simple tricks to use a surrogate key here. Each system can be given a different starting value, but even that can cause problems. GUIDs work, but often affect performance. Another alternative would be a combined field from the system-generated field of the entry and a source code that is used only when connecting the databases. There are other possibilities, although a natural key seems to be the most reasonable option in this situation.
After reading this article you probably wouldn't ask me again, would you? You would, I know it.
Core Dev
New event for statemachines
Statemachines working in combination with UI model can exploit a new feature of the component SuggestText. The SuggestText-component will send an event "onSelection" as soon as the user picked an entry of the popup list. FiledName must be a field definition of the controls section of the statemachine model. The first letter of the name is capitalized to meet the camel Case naming convention. E.g. the field "foo" which is bound to a SuggestText component will emit the event "onFooSelection". Using this event in a statemachine can trigger an action after a user selection of a SuggestText-popup-entry for further processing.
Duplicate translations
Each DSL and some other bundles come with a set of dedicated I18N property files, containing translatable items and the preset amount of target language translations. Each language has its own key-value pairs. The keys are derived from element-ids or other designated translatable strings inside a DSL grammar. All bundles of a product's target platform are scanned for those property files at startup of runtime and translations are cached inside the DSLMetadataService for fast access. By the way, DSLMetadataService also holds the models of all DSL for reference at runtime. Occasionally it happens that the same key is used in different models but with or without valid translation for each target language. There is no need to translate the same key over and over again. Since today there is a method to detect the best translation for each language using the Levenshtein Distance Algorithm. The idea is that the more distant a value is from its key, the better is the translation. On startup, the translation cache is filled with those translations that are most distant from the key. In other words: correct translations that compete against defaults or sloppy translations will make it to the cache, thus increasing the quality of the displayed translation. Additionally there is a new console output indicating duplicates in bundles as error information and surviving translations per language and key as debug information.
Edit WelcomeScreen
As for today it is possible to edit the WelcomeScreen and save the new content permanently in the Preferences of your product.
This is how it works:
Start the application and stay at the Welcome Screen.
With the right-mouse button while holding down the STRG+ALT keys, click 5 times at the top-left area of the Welcome Screen. The sensitive area is 50px in square.
A rich text editor will appear instead of the static screen. Use the tools of the editor and if you are ready, do the 5 times click stuff again to save it and switch back to static mode.
If you want to display images from the in-build themes, you must enter the following path preceding the filename: VAADIN/themes//image/logo_osbee.png for example. It is the currently selected startup theme e.g. osbp.
Here is a list of in-build images you could try (The images are taken from pixabay.com):
2M1AXEU9Q2.jpg
app-loading.jpg
binary-797263_1920.jpg
binary-797274_1920.jpg
bkgnd1.jpg
cpu-564789_1920.jpg
grid-684983_1920.jpg
grid-871475_1920.jpg
key.png
logo_osbee.png
padlock.png
personal-95715_1920.jpg
rain-455120_640.jpg
statistics-706383_1920.jpg
Top_view.jpg
U68NITW3EI.jpg
U68NITW3EI_s.jpg
If you need to restore the original WelcomeScreen just delete the tag welcomeScreen from your preferences file.
Search
When you think about searching and retrieving data, two use cases will come into your mind:
- find an entry of an entity to edit its properties
- find an entity to establish a reference.
For both cases there is a new feature dealing with filters and search views. If you want to pick an entry and don't know exactly its name, you filter all of your entries by means of filtering. There are two types of filters implemented:
- Compare filters (using keyword “filter”)
- Range filters (using keyword “range”)
Compare filters can match an attribute by a set of comparison operators:
- equal
- unequal
- greater
- greater equal
- less
- less equal
- like (you could use the following wildcards:
- % matches any number of arbitrary letters
- $ matches exactly one arbitrary letter).
Range filters expose two fields (from...until) where the inclusive borders of the range can be applied. You can supply filter metadata at the entity model by using the keywords "filter" and "range" like this:
domainKey String fullName
var String firstName
var filter String lastName
var range BirthDate birthDate
var range double salary
this means that "lastName" will have a compare filter, where "birthDate" and "salary" will have a range filter. In addition to this filters on direct attributes it is also possible to walk along the reference tree and add so called nested attributes for filtering. How deep the tree is iterated can be defined in the metadata by using keyword “filterDepth” like this:
ref filterDepth 01 Position position opposite employees
And in the Position entity:
var filter String payType
The keyword “filterDepth” limits the depth of iteration, in the example to 1 iteration. The resulting search view is automatically generated and looks like this:

The filtering can be accessed by the filter button right to the combo-box dropdown-button or you can place a search-view inside a perspective by using this syntax:
part EmployeeSearch spaceVolume "60" view search in MemployeeDto depth 3 filterColumns 1

In the perspective you can override the depth metadata from entity and tell the layouter either to arrange all filtering attributes in 1 column or 2 with the keyword “filterColumns”.
DataInterchange is externally configurable by admins
The latest version of DataInterchange implements a new feature. Whenever the model is saved, not only the java classes and the smooks configuration is written, but also a file to modify the import and export paths is written out. The file is interpreted using the Properties xml import and export method and looks like this:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>dataInterchange file URLs</comment>
<entry key="EmployeesDepartment-import">C:/myimports/employeesdepartment.xml</entry>
<entry key="EmployeesDepartment-export">C:/myexports/employeesdepartment.xml</entry>
</properties>
By default, this file is named like the title in the dataInterchange package and extended by "Config" and has the extension "xml".
package net.osbee.sample.foodmart.datainterchanges title "DataInterchange" {
leads to the filename:
DataInterchangeConfig.xml
and is stored platform independently in the current user's home directory under the subdirectory ".osbee".
An administrator must receive this configuration file with the application, modify it and place it somewhere on the application server. The path to this configuration file must be given in the product's preferences (org.eclipse.osbp.production.prefs):
datainterchange/datainterchangeConfiguration=c\:\\DataInterchangeConfig.xml
The path value obviously depends on your operating system.
In the Eclipse IDE the setting looks like this:

Statemachine (FSM) handles external displays
The latest development for the Statemachine DSL (Finite State-Machine) covers the synchronization of external (slave) browsers to a main (master) browser connected to an OS.bee server. The requirement was mainly inspired by the need of a customer display for the OS.bee POS application OS.pos. In this context it is required parts of the main screen's data which is shared on the slave browser working as a display.
Multiple displays can be connected to a master just by using a pattern on the address line of the slave-browser:
http://{server host-name}/osbpdisplay/#{host-name of the master}-{DisplayName as defined in the ui model}
► e.g.:
http://dv999.compex.de:8081/osbpdisplay/#dv888.compex.de-CustomerDisplay
The FSM supports some new keywords to do so:
-
display <DisplayName> using <DTOName>
-
dto <DTOAlias> type <DTOName> attach <DisplayName>
-
displayText text "some text" @<DisplayName> to <DTOAttribute>
The references of a DTO that is attached to a display are always synchronized across all connected displays. Single fields must be synchronized by displayText.
► e.g.:
dto cashslip type CashSlipDto attach CustomerDisplay
display CustomerDisplay using CustomerDisplayDto
displayText text "locked" @CustomerDisplay to message
► Attention: the formerly used keyword displayText was related to lineDisplays and is now reused for displays. That means for an update to this version, all displayText keywords must be changed to lineDisplayText.
The referenced DTO must be the rootType of the Display definition in the ui model:
display Customer {
rootType CustomerDisplayDto
datasource main:CustomerDisplayDto
verticalLayout left {
textfield(i18n noCaption readonly) message
table(i18n noCaption) slip {
type CashPositionDto
columns {
column quantity
column product.sku
column product.product_name
column price
column amount
}
sort {
column now asc
}
}
align fill-left
bind [this.message].value <--> main.message
bind [this.slip].collection <--> main.slip.positions
}
}
Database Support
Which database systems are supported by the OS.BEE Factory Software? The OS.BEE Software Factory currently supports 4 different database management systems:
The corresponding settings have to be inserted into the product configuration of your application.
Within your Eclipse workspace, open the preferences by clicking to the menu “Window -> Preferences -> OSBP Application Configuration” and choosing first the right product configuration file – the configuration file pointing to your application project (e.g. org.example.yourprojectname.application/.metadata/.plugins/org.eclipse.core.runtime/.settings/org.eclipse.osbp.production.prefs).
Afterwards you can go on to the “Data Source” subsection and enter the information needed for the database you would like to use.

For instance, if you are using an Oracle database as persistence layer for your application, you will set up all the information of the database connection into a JNDI Data Source, in which you will choose the database, its fully classified driver class name and the remaining information such as server name, port and account credentials as shown below.

Similarly you may create further data source instances if needed by duplicating or editing existing ones like shown below for MySQL and H2 In-Memory.


After setting the data sources you would like to use inside your application, all you need to do at last is to specify in each persistence unit instances which data source to use, as shown below.

The persistence units are used on the entity level to identify where certain data are located, in this case in which database. This also gives you the flexibility of storing and retrieving data from multiple data sources. For instance, user credentials (persistence unit: authentication) and other business related data (persistence unit: businessdata) would be stored in an Oracle database whereas business process management (persistence unit: BPM) related data would be stored in a MySQL database due to some organizational decisions… Further information on how data are persisted, can be found in the Entity DSL documentation page.
You may also have a look on the OS.bee Software Factory documentation pages.
Combo box handles now more complex objects
Question:
How to define a combo box that holds an object composed of an id and a label and display only the object label on screen but persist the object id?
Answer:
Until now the type of the object that holds the combo box was also the type for its selection. So it was only possible to persist the type that holds the combo box. The enhancement done on the combo box is that an additional model selection type ("modelSelectionType") can be defined. So the combo box definition can have two different types, one for the objects that the combo box holds in its collection ("type") and another for the information that has to be persisted for the selected object ("modelSelectionType") within the combo box. Due to this change using an object A composed with the attributes id and label from type String a combo box can hold the object A as the type for the container but the type String for the selected item as for example its id. The model to presentation conversion from the container type to the selection type (object A to String) has to be done by an individual converter (as these) implementing YConverter. Example using as type for the collection VaaclipseUiTheme (JavaDoc) and displaying on screen the VaaclipseUiTheme label but persisting its id:
YComboBox yCombo = (YComboBox) ExtensionModelFactory.eINSTANCE.createYComboBox();
yCombo.setUseBeanService(false);
yCombo.setCaptionProperty("label");
yCombo.setType(VaaclipseUiTheme.class);
yCombo.setTypeQualifiedName(VaaclipseUiTheme.class.getCanonicalName());
yCombo.setModelSelectionType(String.class);
yCombo.setModelSelectionTypeQualifiedName(String.class.getCanonicalName());
yCombo.getCollection().addAll(getThemes());
YConverter conv = YConverterFactory.eINSTANCE.createYVaaclipseUiThemeToStringConverter();
yCombo.setConverter(conv);
For more information how to use our combo box have a look on: YComboBox (JavaDoc)
Enriching csv files to highlight complex information
Although it is possible to read and import data from csv files with the help of csv reader tools, the reading process doesn’t consider possible existing relations between the data contained in those files. What is missing here is the possibility to enrich those file with the metadata information needed to highlight the presence of relations between the flat data contained in a bundle of different csv files; thus, giving users the means to set up information over complex structures. With the CSV2App module of the OS.bee Software Factory, you are now able to set additional metadata information into a csv file, by enriching its column definitions. This allows users to define a set of configurations, which will be used to create more complex entity structures, and so forth more complex applications (entities, tables, actions, menus, dialogs…). You can get more information here. You may also have a look on the OS.bee Software Factory documentation pages.
Max File Size BlobMapping
Question:
What is the biggest file size allowed to be imported/uploaded into an OS.bee (created) Software?
Answer:
Some information about the OS.bee BlobMapping data type can be found here. Some information about the database systems currently supported by the OS.bee Software Factory can be found here. You may also have a look on the OS.bee Software Factory documentation pages.
How to show JavaScript compile errors building the Widgetset
Due to a bug in the vaadin-maven-plugin a system property needs to be specified invoking the guid. For normal the -strict option in the pom should do it. But <strict>true</strict> leads to an error, that -failOnError is not a supported option.
Just call the widgetset build by:
mvn clean verify - Dgwt.compiler.strict=true
Then the build will break if errors during the widget set compilation occur. And the console will show the error problems. There is also a similar option -struct. This will break the build even if warnings occur.
Apps
Launch my1app - error
Question:
Following is the error when launching my1app :
java.lang.RuntimeException: Error initializing storage. at org.eclipse.osgi.internal.framework.EquinoxContainer.(EquinoxContainer.java:77) at org.eclipse.osgi.launch.Equinox.(Equinox.java:31) at org.eclipse.core.runtime.adaptor.EclipseStarter.startup(EclipseStarter.java:295) at org.eclipse.core.runtime.adaptor.EclipseStarter.run(EclipseStarter.java:231) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.eclipse.equinox.launcher.Main.invokeFramework(Main.java:648) at org.eclipse.equinox.launcher.Main.basicRun(Main.java:603) at org.eclipse.equinox.launcher.Main.run(Main.java:1465) at org.eclipse.equinox.launcher.Main.main(Main.java:1438) Caused by: java.io.EOFException at java.io.DataInputStream.readInt(DataInputStream.java:392) at org.eclipse.osgi.container.ModuleDatabase$Persistence.readWire(ModuleDatabase.java:1168) at org.eclipse.osgi.container.ModuleDatabase$Persistence.load(ModuleDatabase.java:1028) at org.eclipse.osgi.container.ModuleDatabase.load(ModuleDatabase.java:879) at org.eclipse.osgi.storage.Storage.(Storage.java:145) at org.eclipse.osgi.storage.Storage.createStorage(Storage.java:85) at org.eclipse.osgi.internal.framework.EquinoxContainer.(EquinoxContainer.java:75) ... 11 more An error has occurred. See the log file null.
Answer:
This is kind of OSGi initialization error. Just stop all applications running, restart Eclipse and try again.
Launch my1app - error
Question:
Following is the error when launching my1app :
org.hibernate.tool.hbm2ddl.SchemaExport - HHH000389:unsuccessful : alter table…
Answer:
Just in case you see this error message in the console during the start of your application it might be caused by a missing setting in the Eclipse IDE preferences. Please check the DS annotations setting as mentioned in the installation documentation. After you activate the generation of DS annotations, you have to rebuild the project. Then it starts properly.
Launching an app on OSX results in an endless wait after login
Question:
Launching an app on OSX results in an endless wait after login.
Answer:
If you experience an application hang after the login in an application launch from the Eclipse IDE on OSX, it might have the reason in the automatically created launch configuration. The checkbox "use -XstartOnFirstThread ..." should not be marked. Remove the mark, relaunch the application and it will work.

Update build.properties to make use of new feature
The OS.bee Softwarefactory now creates default icon files in a folder named "enums" in the bundle containing entity model files. It is neccessary to add this folder to the build.properties file of the bundle, otherwise the icons are not available in the final application. A sample build.properties file looks like:
source.. = src/,\
src-gen/
bin.includes = META-INF/,\
.,\
.settings/,\
OSGI-INF/,\
i18n/,\
enums/
How do i get the OS.POS-App started
Question:
There are three steps in the description download = ok extract = ok configure = ???
Answer:
Concerning the configuration of the connected peripheral units, there is a short answer: all peripheral units that can be connected have to follow the JavaPOS specification. There is a configuration file in xml format that has to be edited by programs of the peripheral hardware vendor. E.g. if you have Epson hardware, you must install the EPSON_JavaPOS_ADK_1143. After installing the appropriate drivers and programs , you can start "SetupPOS" and configure a POSPrinter, LineDisplay and CashDrawer, test their health with "CheckHealth". The path of the newly created configuration xml must be entered in the preferences file, then you can start OS.bee. There is a lot of configuration stuff in the preferences file which will be published step by step. Best way to edit is inside an Eclipse IDE under "OSBP Application Configuration".
Copyright Notice
All rights are reserved by Compex Systemhaus GmbH. In particular, duplications, translations, microfilming, saving and processing in electronic systems are protected by copyright. Use of this manual is only authorized with the permission of Compex Systemhaus GmbH. Infringements of the law shall be punished in accordance with civil and penal laws. We have taken utmost care in putting together texts and images. Nevertheless, the possibility of errors cannot be completely ruled out. The Figures and information in this manual are only given as approximations unless expressly indicated as binding. Amendments to the manual due to amendments to the standard software remain reserved. Please note that the latest amendments to the manual can be accessed through our helpdesk at any time. The contractually agreed regulations of the licensing and maintenance of the standard software shall apply with regard to liability for any errors in the documentation. Guarantees, particularly guarantees of quality or durability can only be assumed for the manual insofar as its quality or durability are expressly stipulated as guaranteed. If you would like to make a suggestion, the Compex Team would be very pleased to hear from you.
(c) 2016-2026 Compex Systemhaus GmbH